
Si la révolution de l'IA a donné lieu à une vérité universelle en matière de gestion des données, c'est bien la nécessité d'ouverture et d'interopérabilité à travers l'ensemble du parc de données. Après tout, l'IA n'est efficace que dans la mesure où elle peut réellement accéder aux données.
Les entreprises ne sont plus disposées à investir dans des technologies patrimoniales déconnectées. Le coût des silos, autrefois mesuré uniquement en infrastructure, est maintenant exponentiellement plus élevé lorsqu'il est mesuré en temps de valeur perdu et en incapacité à exécuter l'IA à grande échelle. Dans ce contexte, les entreprises ne peuvent pas se permettre de ne pas repenser leurs architectures de données.
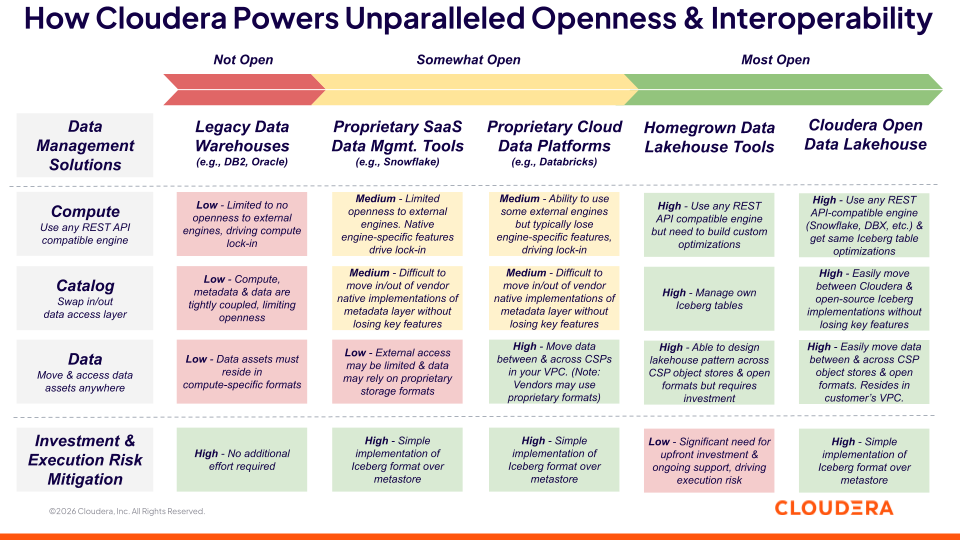
Chez Cloudera, nous définissons l'ouverture comme une architecture de gestion des données à trois niveaux (voir figure 1) :
Informatique ouverte : la possibilité d'utiliser n'importe quel moteur, quel que soit l'endroit où les données sont stockées
Catalogue ouvert : La possibilité d'intégrer et de désintégrer, et d'inter-opérer à travers différentes couches d'accès aux données, garantissant la cohérence du schéma et de la gouvernance quel que soit le moteur de visualisation.
Données ouvertes : la possibilité de déplacer et d'accéder à des actifs de données où qu'ils se trouvent
D'une manière plus générale, l'ouverture est au cœur de notre identité chez Cloudera :
Pionnier d'Apache Iceberg : Cloudera a commencé à prendre en charge Iceberg dans son cloud public Lakehouse en 2021. D'autres fournisseurs ont rapidement emboîté le pas, reconnaissant implicitement Iceberg comme le vainqueur de la guerre des formats de table ouverts. En 2024, Databricks a acquis Tabular, en partie grâce à sa gouvernance ouverte et ses fonctionnalités sophistiquées. En 2025, à la fois Snowflake et Amazon Web Services (AWS) ont investi dans l'expansion du support et des fonctionnalités d'Iceberg.
Fondation et écosystème open source : Profondément ancrée dans la communauté open source depuis sa création en 2008, Cloudera a été la première entreprise à commercialiser la technologie open source de lac de données et continue de contribuer et de soutenir plus de 50 projets open source. Notre fondation open source offre une liberté de choix en permettant à nos clients d'opter pour les distributions Cloudera ou de les abandonner bien plus facilement que les fournisseurs qui les verrouillent par des couches propriétaires. Les clients de Cloudera ne sont pas obligés de rester ; ils choisissent de rester.
Interopérabilité à travers la pile de gestion des données : Fournir un calcul, un catalogue et des données ouverts garantit l'interopérabilité à chaque niveau de la pile de gestion des données afin que nos clients puissent vraiment gagner à l'ère de l'IA sans avoir à tout construire à partir de zéro. De plus, Cloudera offre la flexibilité d'utiliser n'importe quel moteur de calcul ou de stocker des données chez n'importe quel fournisseur de services cloud (CSP), et fournit un accès complet aux fonctionnalités, peu importe où se trouvent les données ou quel moteur de calcul est utilisé. À l'inverse, certains fournisseurs restreignent l'accès aux fonctionnalités selon que toutes les couches de la pile sont exécutées sur la même plateforme. Possédez vos données. Contrôlez vos données. Utilisez vos données : telle est la promesse de Cloudera.
Pour en savoir plus sur l'importance de l'ouverture à l'ère de l'IA, lisez notre blog : L'avenir livré aujourd'hui : l'entrepôt de données alimenté par l'IA.
