Cloudera AI Inference Service
Accélérez la mise en service des modèles pour déployer et faire évoluer des applications, des agents et des assistants d'IA privés avec une rapidité, une sécurité et une efficacité inégalées.

Boostez le développement et le déploiement de l'IA tout en sécurisant chaque étape de son cycle de vie.
Optimisée par les microservices NVIDIA NIM, la solution Cloudera AI Inference Service offre des performances de pointe : des inférences jusqu'à 36 fois plus rapides sur les GPU NVIDIA et un débit près de 4 fois supérieur sur les CPU. Elle rationalise ainsi la gestion et la gouvernance de l'IA de manière transparente sur les clouds publics et privés.
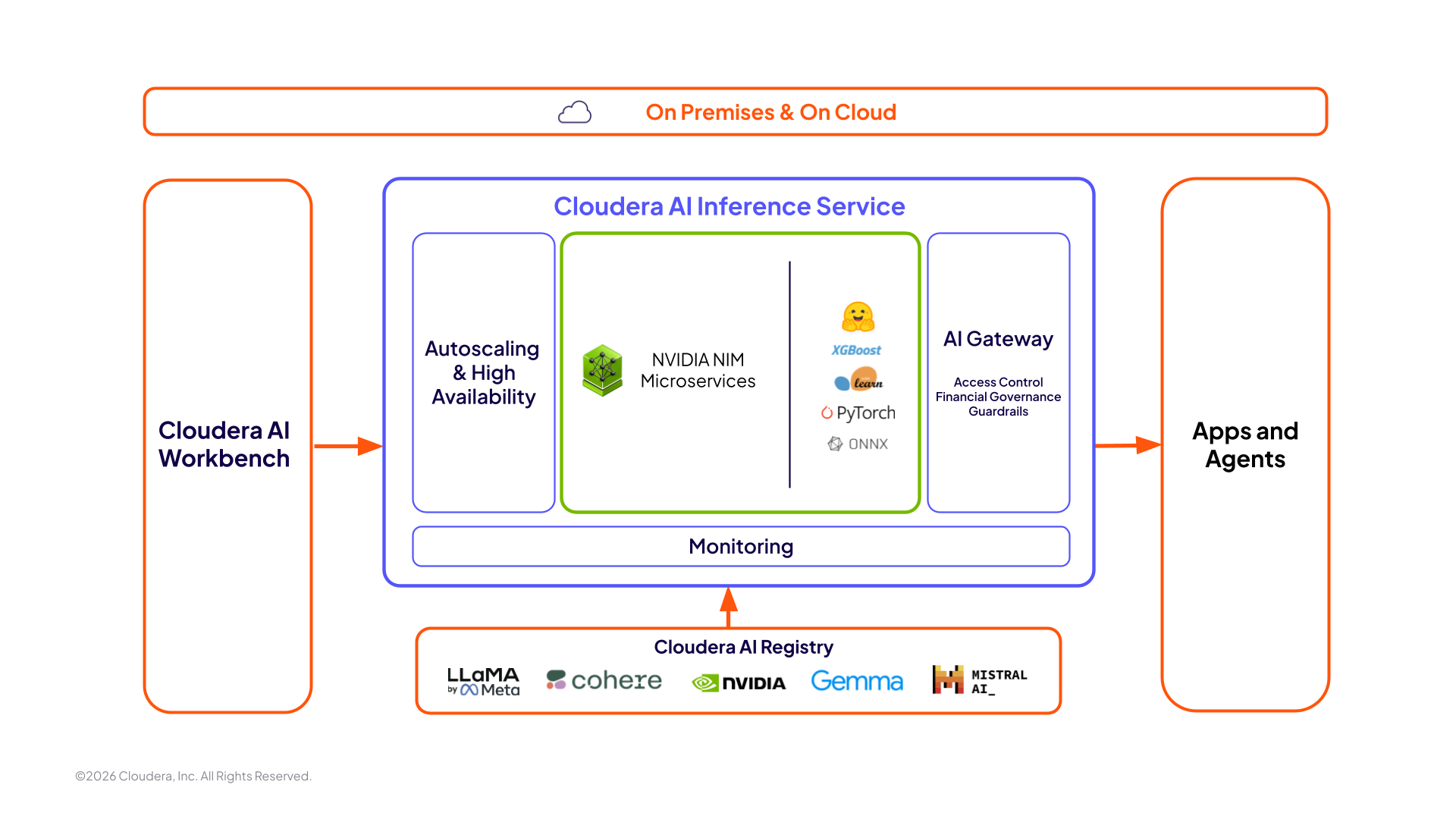
Un service unique pour tous vos besoins d'inférence d'IA d'entreprise
Déploiement en un clic : faites passer rapidement votre modèle du développement à la production, quel que soit l' environnement.
Environnement unique et sécurisé : bénéficiez d'une sécurité de bout en bout couvrant toutes les étapes du cycle de vie de votre IA.
Plateforme unique : gérez facilement tous vos modèles grâce à une plateforme unique qui répond à tous vos besoins en matière d'IA.
Assistance centralisée : bénéficiez d'une assistance unifiée de la part de Cloudera pour toutes vos questions relatives au matériel et aux logiciels.
Principales fonctionnalités d'AI Inference Service
Options de déploiement d'AI Inference Service
Exécutez des charges de travail d'inférence sur site ou dans le cloud, sans compromettre les performances, la sécurité ou le contrôle.
Cloudera dans le cloud
- Flexibilité multicloud : effectuez vos déploiements sur différents clouds publics et évitez l'enfermement dans un écosystème particulier.
- Rentabilité plus rapide : commencez à inférer sans avoir à configurer d'infrastructure, l'idéal pour des expérimentations rapides.
- Évolutivité flexible : gérez le trafic imprévisible grâce au dimensionnement automatique « scale-to-zero » et aux microservices optimisés par GPU.
Cloudera sur site
- Souveraineté des données : gardez un contrôle total. Conservez les modèles, les invites et les actifs entièrement derrière votre pare-feu.
- Isolement physique : conçu pour les environnements réglementés tels que les services gouvernementaux, le secteur de la santé et les services financiers.
- Coût total de possession prévisible et réduit : éliminez les surprises grâce à une tarification fixe et un coût total de possession réduit par rapport aux API cloud basées sur des jetons.
DÉMO
Déploiement de modèles sans effort
Découvrez avec quelle facilité vous pouvez déployer de grands modèles de langage et gérer efficacement des applications d'IA à grande échelle grâce aux puissants outils Cloudera.

Intégration du référentiel de modèles :
Accédez aux modèles, stockez-les, mettez-les à jour et gérez-les facilement par le biais du référentiel centralisé Cloudera AI Registry.
Configuration et déploiement faciles : Déployez des modèles dans des environnements cloud, configurez des points de terminaison et ajustez le dimensionnement automatique pour plus d'efficacité.
Surveillance des performances :
Résolvez les problèmes et optimisez les performances en vous basant sur des indicateurs clés tels que le temps de latence, le débit, l'utilisation des ressources et l'état de santé des modèles.

Cloudera AI Inference vous permet d'exploiter le plein potentiel des données à grande échelle grâce à l'expertise de NVIDIA en matière d'IA. Des fonctionnalités de sécurité de pointe vous permettent de protéger vos données en toute confiance et d'exécuter des charges de travail sur site ou dans le cloud tout en déployant efficacement des modèles d'IA avec la flexibilité et la gouvernance nécessaires.
Vous en voulez plus ?
Passez à l'étape suivante
Découvrez des capacités puissantes et approfondissez vos connaissances grâce à des ressources et des guides qui vous permettront de vous lancer rapidement.
Présentation du produit AI Inference Service
Découvrez le service Cloudera AI Inference.
Documentation du service d'inférence d'IA
Vous y trouverez tout ce dont vous avez besoin, de la description des fonctionnalités aux guides de mise en œuvre.
Découvrez d'autres produits
Accélérez la prise de décision basée sur les données, de la recherche à la production, grâce à une plateforme sécurisée, évolutive, ouverte et dédiée à l'IA d'entreprise.
Accédez à des workflows privés agentiques et d'IA générative pour tous les niveaux de compétence, avec une rapidité low-code et un contrôle full-code.
Mettez la puissance de l'IA au service de votre entreprise en toute sécurité et à grande échelle, en veillant à ce que chaque information soit traçable, explicable et fiable.
Découvrez le framework de bout en bout permettant de créer, de déployer et de surveiller instantanément des applications de machine learning prêtes à l'emploi.