
Les fondations ouvertes de Cloudera permettent aux organisations d'accéder à 100 % de leurs données, où qu'elles se trouvent
Dans tous les secteurs, les équipes chargées des données repensent la manière de construire et d'exploiter des systèmes qui ne se contentent pas de stocker des informations : elles cherchent à transformer les données en intelligence. Il est tout aussi important que ces systèmes soient capables d'interopérer. Les modèles d'IA, les pipelines de fonctionnalités, les rapports de veille stratégique (BI) et les tâches par lots s'étendent souvent sur plusieurs équipes et moteurs. Partager des données au-delà de ces frontières sans les copier ni les remanier est désormais une exigence de premier ordre.
Traditionnellement, les organisations s'appuient sur une architecture à deux niveaux : des Data Warehouse optimisés pour la BI et le reporting, et des lacs de données conçus pour l'IA et le Machine learning (ML) à grande échelle. Cette séparation a eu un coût : des transferts de données complexes, une ingénierie spécialisée et un stockage dupliqué sur des systèmes rarement synchronisés.
L’architecture open lakehouse de Cloudera répond à ce défi, réunissant des charges de travail analytiques (BI, requêtes ad hoc) et IA (IA prédictive et générative, ou GenAI) sur une base de données unique et gouvernée. Avec des formats de table ouverts comme Apache Iceberg, cette architecture de données unifiée permet aux organisations d'apporter le calcul aux données (et non l'inverse) et fournit la base pour exécuter des charges de travail d'IA plus proches des données. Les charges de travail d'IA sur le data lakehouse peuvent fonctionner directement sur des données gouvernées, versionnées et de haute qualité.
Cloudera est la seule entreprise de plateformes de données et d'IA qui met l'IA au service des données partout. En tirant parti de notre fondation open source éprouvée, nous offrons une expérience cloud homogène qui combine les clouds publics, les centres de données et la périphérie du réseau.
L'importance des fondements ouverts pour l'exécution de charges de travail d'IA
Au cours de la dernière décennie, les entreprises ont appris que la performance et l'évolutivité seules ne suffisent pas, et que la flexibilité et l'interopérabilité déterminent le succès à long terme. Les charges de travail de l'IA, en particulier, dépendent de la capacité à utiliser des sources de données, des frameworks et des outils disparates, sans être contraints par des formats ou des systèmes propriétaires.
C’est là que les formats de table ouverte comme Apache Iceberg ont transformé l’architecture des plateformes de données. Iceberg sépare la définition logique d'une table de sa disposition de stockage physique, permettant à plusieurs moteurs et frameworks de lire et d'écrire les mêmes données avec des garanties transactionnelles complètes. Cette ouverture permet de faire évoluer l'infrastructure et d'adopter de nouveaux moteurs de calcul sans réécrire les pipelines.
L'exécution de pipelines de production nécessite une plateforme unifiée capable de connecter les données, les modèles et la gouvernance à chaque étape du cycle de vie de l'IA. Au cœur du système, il existe des pipelines d'ingénierie de données et de fonctionnalités qui transforment continuellement des données brutes structurées, semi-structurées et non structurées en caractéristiques prêtes pour l'IA, en maintenant la lignée et la reproductibilité pour l'entraînement et l'évaluation des modèles.
Au-delà de l'apprentissage automatique traditionnel, l'IA générative introduit de nouvelles exigences opérationnelles. Les équipes ont besoin d'une infrastructure et d'un accès aux données pour la génération augmentée par récupération (RAG), le réglage fin de grands modèles de langage (LLM) sur des données privées, et la création de flux de travail agentiques qui combinent des modèles, des invites et des protocoles de contexte de modèle (MCP) (API) pour résoudre des tâches spécifiques à un domaine. Ces charges de travail reposent sur des données à la fois tabulaires et non structurées (texte, documents, images et intégrations) — toutes gérées sous un seul plan de données et de métadonnées. De plus, une couche d’inférence évolutive est essentielle pour déployer et servir ces modèles de manière sûre et efficace.
Les charges de travail de l'IA devenant de plus en plus multimodales et agentiques, l'accès aux catalogues et aux métadonnées devient tout aussi essentiel. Les pipelines d'IA, les systèmes de récupération et les agents autonomes reposent tous sur les métadonnées pour découvrir les ensembles de données, reproduire les états d'entraînement et maintenir la traçabilité. Un catalogue ouvert offre à ces systèmes un moyen universel d'interroger, d'enregistrer et de suivre les ensembles de données, indépendamment du lieu ou de la manière dont ils sont traités.
La fondation ouverte de Cloudera permet aux organisations de prendre en charge le spectre complet des charges de travail analytiques, prédictives et GenAI.
La plateforme unifiée de données et d’IA de Cloudera
Le lac de données ouvert de Cloudera unifie l'ingénierie des données, l'analyse et l'IA sur la même architecture gouvernée en s'appuyant sur des fondations ouvertes telles qu'Apache Iceberg et le catalogue REST. La plateforme est conçue selon le principe que les charges de travail (qu'elles soient analytiques ou liées à l'IA) devraient opérer là où les données se trouvent déjà. En éliminant les frictions liées au déplacement ou à la duplication des données, les équipes peuvent créer des pipelines continus qui couvrent les opérations d'ingestion, de transformation, d'analyse et de modélisation, avec un suivi et une gouvernance complets.
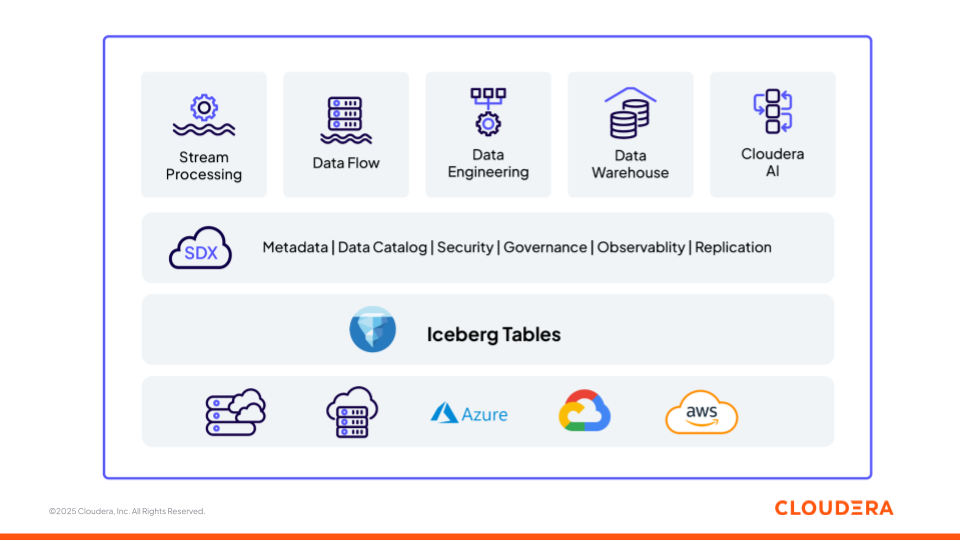
Figure 1 : La plateforme de données et d'IA de Cloudera repose sur des bases ouvertes (Apache Iceberg)
Nous allons maintenant examiner comment les différents composants de la plateforme Cloudera (Figure 1) soutiennent les équipes dans la construction de pipelines ML et d’applications GenAI, ainsi que les différentes étapes du cycle de vie des données et de l’IA — de l’ingestion à l’inférence — tout en fonctionnant comme une plateforme interopérable. Chaque composant est construit sur des standards ouverts, garantissant flexibilité et interopérabilité entre environnements.
Stockage : Apache Iceberg
Apache Iceberg est le format de table ouverte, versionné et transactionnel qui sous-tend l’architecture lakehouse de Cloudera. Iceberg permet l'évolution des schémas, le voyage dans le temps et les opérations atomiques, permettant aux charges de travail analytiques et d'IA de fonctionner de manière cohérente sur les mêmes données gouvernées. Cloudera offre une base gouvernée et versionnée qui garantit que chaque modèle, prompt ou tâche de récupération s’appuie sur une vue cohérente et traçable des données.
Les capacités natives d’Iceberg, telles que l’évolution des schémas, s’alignent également sur l’évolution des ensembles de données d’IA. Les magasins de fonctionnalités, les ensembles de données d’entraînement et les corpus de récupération peuvent tous partager les mêmes tables Iceberg dans le lakehouse de Cloudera, en utilisant des instantanés pour figer des vues cohérentes pour l’entraînement tandis que de nouvelles données continuent d’affluer pour l’inférence. Il n'y a donc plus de clivage entre les tables analytiques et le stockage spécifique à l'IA.
Ingestion : données en mouvement avec Cloudera
Cloudera DataFlow, basée sur Apache NiFi, constitue la base d'un mouvement continu des données vers le Lakehouse. Elle permet l'ingestion à faible latence à partir de diverses sources d'entreprise (bases de données, API, appareils IoT et journaux d'événements) afin de prendre en charge les charges de travail en mode batch et en mode streaming. Des innovations récentes dans l'intégration native d'Apache Iceberg de NiFi permettent maintenant d'écrire des données directement dans le lac ouvert sans étape intermédiaire. Cette étroite connexion entre NiFi et Iceberg réduit la complexité du pipeline et rapproche l'ingestion du format de table ouvert lui-même.
Dans les cas d'utilisation en temps réel, NiFi, Apache Kafka et Apache Flink forment une structure d'ingestion pilotée par les événements : NiFi orchestre et achemine les données, Kafka fournit un streaming durable, et Flink permet un enrichissement en temps réel avant de persister les données dans Iceberg. Cette conception garantit que les données restent à la fois fraîches et régies pour tous les consommateurs en aval. Ce flux continu de données multimodales est également ce qui alimente les charges de travail IA sur le lakehouse. En rendant les données en temps réel continuellement disponibles dans les tables Iceberg sous une gouvernance cohérente, les entreprises peuvent alimenter les systèmes d'IA générative avec des informations opportunes et spécifiques au domaine, rendant les pipelines RAG et les flux de travail agentiques plus précis, ancrés et fiables.
Catalogue : Cloudera Iceberg REST Catalog
Le catalogue REST Cloudera Iceberg (basé sur la spécification REST ouverte) fournit un service de métadonnées centralisé et interopérable qui permet à tout moteur tiers (tel que Snowflake, Redshift et Databricks) prenant en charge la spécification ouverte d'avoir un accès sans copie aux tables Iceberg. Il s'agit d'un aspect essentiel pour les entreprises, car elles ne sont pas limitées à un seul moteur de calcul offert par une plateforme et ont donc la possibilité de choisir le meilleur moteur de calcul pour la tâche à accomplir. Les utilisateurs peuvent utiliser leurs outils préférés tandis que les mêmes politiques de sécurité et de gouvernance offertes par Cloudera suivent les données partout, garantissant ainsi la cohérence entre les environnements.
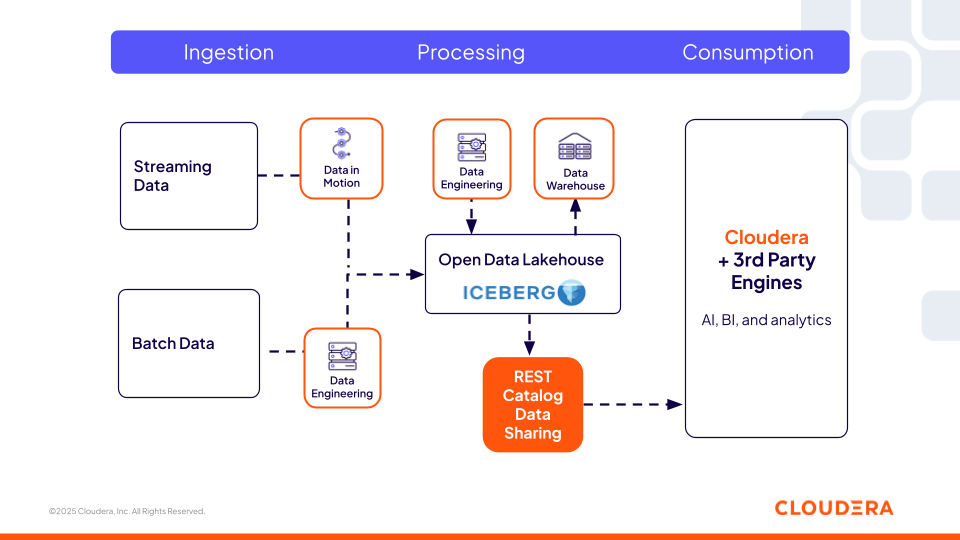
Figure 2 : Le catalogue REST Iceberg de Cloudera permet l'interopérabilité avec les moteurs tiers
Cette couche de catalogue est essentielle pour les pipelines d'ingénierie des fonctionnalités, les flux de travail agentiques et les systèmes de récupération pour localiser et accéder dynamiquement aux ensembles de données gouvernés. Les agents d'IA peuvent interroger les tables Iceberg en utilisant le catalogue REST Iceberg, tout comme un graphe de connaissances des données d'entreprise. Ils peuvent découvrir les tables disponibles, interpréter leurs schémas et raisonner sur les métadonnées des tables, telles que le partitionnement, les instantanés et le lignage, afin de déterminer les ensembles de données à utiliser.
Sécurité et gouvernance : Cloudera SDX
Cloudera Shared Data Experience (SDX) est le cadre unifié de sécurité et de gouvernance qui couvre chaque service, de l’ingestion à l’inférence. SDX fournit une couche unique et cohérente pour le lignage des données, l'audit, le contrôle d'accès et l'application des politiques, garantissant que chaque charge de travail hérite du même modèle de sécurité, quel que soit son lieu d'exécution. Il s’intègre aux systèmes d’identité d’entreprise (LDAP, SSO, OAuth) et prend en charge des contrôles d’accès précis, basés sur les rôles et attributs, à travers des données structurées et non structurées.
En associant SDX à la fondation ouverte Lakehouse, Cloudera garantit que les données, les modèles et les agents d'IA fonctionnent dans les mêmes limites gouvernées, assurant la transparence, la reproductibilité et la confiance pour les charges de travail analytiques et GenAI.
Cloudera Data et IA Services
La couche de services unifiés rassemble toutes les capacités fonctionnelles dont les équipes ont besoin pour transformer, analyser et opérationnaliser l'IA, tout en travaillant sur les mêmes données gouvernées.
Data Engineering
Cloudera Data Engineering, construit sur Apache Spark et Apache Airflow open source, offre un service serverless pour construire, orchestrer et faire évoluer des pipelines de données directement sur des tables Iceberg — permettant des pipelines ETL et de fonctionnalités fiables et reproductibles pour les charges d’analyse et d’IA dans des environnements hybrides.
Services d'IA
La couche de services d'IA de Cloudera opérationnalise l'ensemble du cycle de vie de l'IA, en commençant par la formation et l'ajustement fin des modèles jusqu'au déploiement sécurisé, le tout s'exécutant nativement sur la même base de données gouvernée avec Iceberg. Il unifie le développement de modèles, le registre et l'inférence en un seul workflow qui relie l'ingénierie des données et les opérations d'IA.
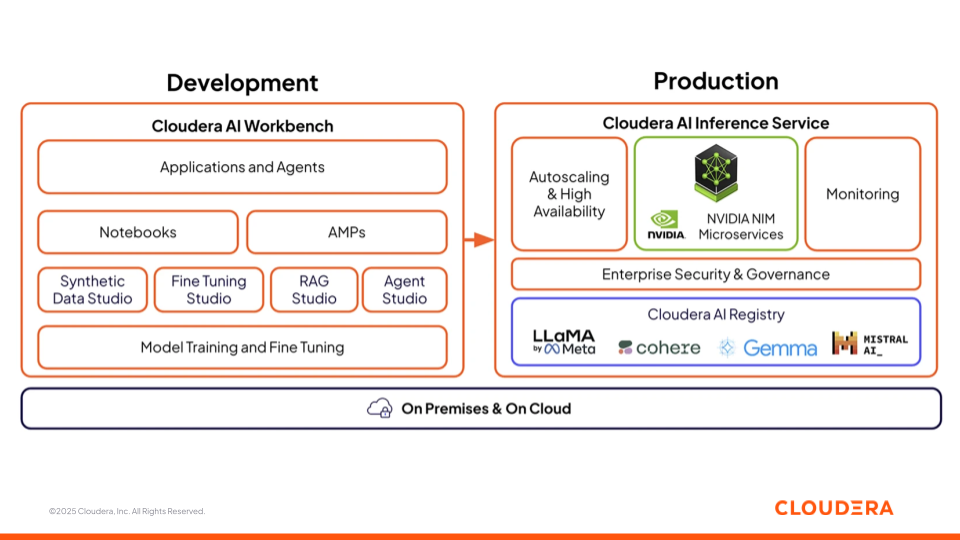
Figure 3 : L'offre de Cloudera AI avec AI Workbench et un service d'inférence
Cloudera AI Workbench
Cloudera AI Workbench est l’environnement collaboratif où les data scientists, analystes et ingénieurs développent, affinent et testent des modèles. Il rassemble des notebooks, des constructeurs d'applications low-code (AMP), et des studios spécialisés pour chaque étape du développement de l'IA. Pour accélérer le développement et le déploiement de l’IA, Cloudera AI Workbench soutient quatre studios d’IA qui font le lien entre les équipes métier et techniques, favorisant la collaboration sur des projets d’IA.
- Synthetic Data Studio génère des ensembles de données synthétiques pour les tests et l'apprentissage de modèles lorsque les données réelles sont limitées ou restreintes.
- Fine-Tuning Studio adapte les modèles de base ouverts avec des ensembles de données spécifiques à l'entreprise pour une pertinence et une précision accrues.
- RAG Studio construit des pipelines RAG qui relient des LLM (tels qu’OpenAI, Anthropic, Amazon Bedrock) à des données privées pertinentes pour des sorties contextuelles et ancrées.
- Agent Studio permet de créer des flux de travail agentiques en plusieurs étapes qui utilisent des modèles, des MCP, des API et des sources de données internes pour automatiser les tâches spécifiques à un domaine.
Toutes ces fonctionnalités fonctionnent à ciel ouvert (sur les fondations d'Iceberg), donnant aux équipes un accès contrôlé et sans copie aux données nécessaires à des tâches spécifiques.
Serveur MCP Cloudera
Cloudera étend également l’ouverture de sa plateforme d’IA à travers une série de services MCP émergents, à commencer par le serveur open source Cloudera AI Workbench MCP. Ce service est conçu pour l'intégration de systèmes d'IA, permettant des capacités agentiques et d'appel d'outils au sein de l'AI Workbench. Il fournit le cadre permettant aux LLM d'interagir en toute sécurité avec les fonctionnalités et les composants de Cloudera AI Workbench, intégrant ainsi les modèles, les données et les applications dans des flux de travail d'entreprise automatisés. Dans cette architecture, les agents intelligents peuvent raisonner, agir et automatiser des tâches dans l'environnement Cloudera fiable et gouverné, tout en maintenant la sécurité, le contrôle et l'auditabilité requis dans les secteurs réglementés.
Cloudera AI Inference Service
Le Cloudera AI Inference Service met les modèles en production avec une mise à l'échelle automatique, une haute disponibilité et une observabilité de bout en bout. Il prend en charge à la fois les modèles ML traditionnels et les grands modèles de langage (LLM), fournissant des prédictions et des réponses avec une faible latence. Les modèles peuvent être déployés en terminaux REST ou gRPC avec une sécurité de niveau entreprise, garantissant un accès fiable et cohérent depuis les applications et les agents.
Le Cloudera AI Registry, intégré dans la couche d’inférence, offre une gestion centralisée du cycle de vie du modèle avec des API compatibles MLflow pour le suivi, le versionnement, le stockage d’artefacts et la lignée. Vous avez la possibilité de choisir parmi les différentes options de modèles linguistiques ouverts et d'entreprise tels que LlaMa, Cohere, Gemma, Mistral.
La couche d'inférence comprend également une surveillance et une observabilité intégrées, permettant aux équipes de suivre la latence, le débit et la dérive du modèle tout en conservant un suivi complet et une conformité grâce à la gouvernance SDX. Cela garantit que les prédictions du modèle sont explicables et traçables, ce qui est une exigence clé pour l'IA d'entreprise.
L'avenir est piloté par l'IA, et l'IA est alimentée par toutes les données
Le succès de l'IA dépend autant de l'architecture des données que de la capacité du modèle/agent. Le lakehouse fournit cette base, en unifiant les charges de travail analytiques, opérationnelles et d'IA sur un seul plan de données gouverné. Lorsqu'il est construit sur des normes ouvertes, il garantit que les données, les métadonnées et les modèles peuvent interopérer entre les outils, les clouds et les équipes sans friction.
Ensemble, Cloudera AI Workbench, AI Inference Service et le registre d'IA intégré complètent le cycle de vie des données vers l'IA sur une plateforme ouverte de type « lakehouse ». Construit directement sur des tables Iceberg gouvernées et un accès ouvert aux métadonnées, cette pile garantit que chaque modèle, invite et agent fonctionne sur des données fiables et versionnées.
L’avenir de l’IA d’entreprise ne sera pas défini par des piles propriétaires, mais par des fondations ouvertes qui unifient les données, la gouvernance des données et l’intelligence grâce à des normes partagées et une interopérabilité transparente.
Pour en savoir plus sur la façon de préparer, intégrer et analyser des données à grande échelle en toute sécurité avec Cloudera, consultez nos démonstrations de produits ou inscrivez-vous pour un essai gratuit de 5 jours.
