Démocratiser les données pour l’IA en utilisant l’interopérabilité entre les moteurs et la collaboration de données sans copie




Comment le catalogue REST Iceberg de Cloudera permet aux entreprises ouvertes et prêtes pour l’IA
L'interopérabilité a longtemps été un mot à la mode, et non une capacité sur laquelle les entreprises peuvent compter en pratique. Au lieu de cela, les architectes de données sont souvent contraints d'assembler des systèmes fragmentés, les directeurs des données font face à des risques massifs et à l'enfermement chez un fournisseur en raison d'une gouvernance cloisonnée, et les leaders de plateforme sont empêchés de fournir une vue cohérente des données à leurs équipes. Qu'il s'agisse de fusions, de stratégies multi-cloud ou de partenariats externes, le schéma se répète : augmentation des coûts, ralentissement de l'innovation et capacité limitée à développer l’intelligence artificielle en toute confiance.
Chez Cloudera, nous avons aidé nos clients à surmonter ces défis — des couches de métadonnées déconnectées, des pipelines de données dupliqués et des modèles de gouvernance qui ne parviennent pas à s'étendre à travers les outils — en nous efforçant toujours de permettre aux entreprises ouvertes et prêtes pour l'IA de débloquer l'interopérabilité à grande échelle.
Pourquoi l'ouverture est importante pour l'IA d'entreprise
Pour faire évoluer les charges de travail d’intelligence artificielle, les entreprises ont besoin de visibilité et de contrôle sur les données qui les alimentent. L’intelligence des métadonnées joue un rôle essentiel dans cette équation, en permettant aux organisations de comprendre où se trouvent les données, comment elles sont structurées et comment elles sont utilisées par les équipes et les outils.
Grâce à des normes ouvertes telles qu'Apache Iceberg et le catalogue REST Iceberg, les entreprises bénéficient d'une couche unifiée de métadonnées qui prend en charge le partage de données sans ETL, renforce la gouvernance et favorise l'interopérabilité sécurisée entre les moteurs d'analyse et d'intelligence artificielle. Cette fondation transforme une infrastructure fragmentée en une architecture de données connectée et prête pour l'intelligence artificielle, où les métadonnées deviennent la clé pour accélérer l'accès aux informations tout en maintenant la confiance.
Ouvert, sécurisé et simple : le catalogue REST Cloudera Iceberg
Le catalogue REST Iceberg de Cloudera alimente notre data lakehouse ouvert et aide les organisations à simplifier l'architecture, à réduire les duplications et à étendre l'accès sécurisé aux données partout où c'est nécessaire.
Il agit comme une couche universelle et interopérable de métadonnées et offre un accès sans copie aux tables Iceberg à travers les outils, clouds et équipes, permettant aux outils open source et tiers d’accéder aux mêmes données. Les caractéristiques et avantages incluent :
- Ouvert et indépendant des moteurs : fournit des API basées sur des standards qui prennent en charge des outils tels qu'Athena, Databricks, Redshift et Snowflake, permettant ainsi une interopérabilité sans dépendance vis-à-vis d'un fournisseur.
- Découplé par conception: Les moteurs de requête sont abstraits des métastores du backend, ce qui réduit la complexité et augmente la portabilité dans différents environnements.
- Accès aux métadonnées en temps réel: Prise en charge de requêtes de métadonnées rapides et actualisées à partir de métastores compatibles avec Iceberg, améliorant ainsi la visibilité des données au sein des équipes.
- Gouverné et sécurisé: Étend les contrôles d'accès à grain fin, les autorisations au niveau des lignes et l'intégration de la gestion de l'accès à l'identité (IAM) de l'entreprise (comme LDAP et OAuth2) à tous les systèmes connectés, garantissant ainsi une application cohérente des politiques à l'échelle.
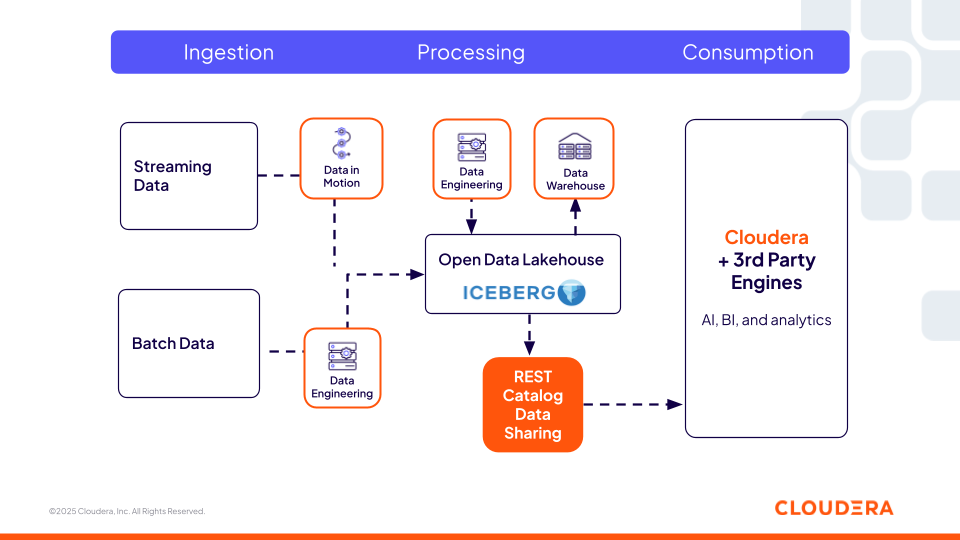
Figure 1. Le catalogue Iceberg REST de Cloudera offre une couche universelle et interopérable de métadonnées, permettant aux outils open source et tiers d’accéder aux mêmes données.
Cas d'utilisation réels et impact du catalogue REST Iceberg
Les exemples suivants illustrent comment les entreprises utilisent le catalogue REST d’Iceberg pour simplifier leur infrastructure de données, réduire le coût total de possession (TCO) et accélérer la création de valeur — tout en conservant les données là où elles doivent être.
Ensemble, ces exemples démontrent comment l'approche ouverte et interopérable de Cloudera accélère les résultats de l'IA, améliore l'efficacité opérationnelle à l'échelle de l'entreprise et garantit la sécurité et la conformité.
Partage de données : étendez les applications d'IA à plus de 3 000 utilisateurs multiplateformes.
Un constructeur automobile de luxe a rencontré des défis croissants pour partager des données en toute sécurité avec un partenaire externe utilisant Databricks. Les méthodes traditionnelles reposaient sur la duplication des données, ce qui entraînait des coûts, de la complexité et une rigidité architecturale.
En adoptant le catalogue REST d'Iceberg, le client a mis en place un partage de données sécurisé, sans ETL, entre les systèmes internes et les plateformes externes. Cette approche ouverte et basée sur des standards leur a permis de choisir les meilleurs outils pour le travail, en utilisant Spark pour les pipelines de données complexes et Impala pour les analyses SQL rapides. Grâce à cette base, l'entreprise a pu étendre ses applications d'IA à plus de 3 000 utilisateurs tout en maintenant une gouvernance et un contrôle complets sur l'accès aux données.
Optimisation des Data Warehouse : réduire les coûts de déplacement des données de 74 %
Suite à une activité de fusion, une société mondiale de satellites a rencontré d'importants obstacles dans l'unification de données fragmentées verrouillées dans des systèmes propriétaires. Sans une couche de données cohérente et interopérable, leurs initiatives en matière d'IA et d'analyse étaient lentes à évoluer et difficiles à gérer.
L'architecture de data lakehouse ouvert de Cloudera, alimentée par le catalogue REST Iceberg, a aidé le client à consolider ces silos et à établir une source unique de vérité pour toutes ses charges de travail d'IA et d'analyse. En interrogeant les tables Iceberg gérées directement dans S3, ils ont éliminé le besoin de pipelines de données redondants et d'efforts de re-platformage, ce qui a entraîné une réduction de 74 % des coûts de déplacement des données.
Démo : Un regard approfondi sur le partage de données via le catalogue REST Iceberg de Cloudera
Cette démonstration interactive donne vie au catalogue REST Iceberg à travers un scénario de services financiers. À la banque mère fictive, différentes équipes utilisent leurs outils préférés — comme Snowflake et AWS Athena — pour accéder en toute sécurité à une seule source de données gouvernée, le tout sans ETL complexe ni déplacement coûteux de données.
Pour en savoir plus sur cette offre, et sur les avantages qu'elle peut apporter à votre organisation, consultez les ressources suivantes :
- Visitez notre page produit pour en savoir plus sur le data lakehouse ouvert de Cloudera.
- Lisez le communiqué de presse pour l’annonce complète de la vision de Cloudera en matière de partage ouvert des données.