
Les stratégies de croissance inorganique, telles que les fusions et acquisitions (F&A), servent de leviers stratégiques de croissance, permettant aux entreprises de réaliser des synergies de revenus et de coûts ou d’acquérir rapidement des capacités émergentes qui offriront un avantage concurrentiel à long terme. Aujourd'hui, par exemple, nous observons de grandes organisations qui acquièrent de petites start-ups innovantes dans le domaine de l'IA afin d'accélérer leurs efforts de transformation de l'IA et d'acquérir un avantage concurrentiel.
L'intégration technologique joue un rôle crucial dans l'acquisition de la valeur de M&As. Selon une étude de Deloitte, l'informatique est l'un des principaux moteurs des avantages de l'intégration, puisqu'elle représente plus de 50 % de toutes les synergies. Cependant, en raison de la prolifération des silos de données et des architectures technologiques et environnements variés, les organisations font face à plusieurs défis post-fusion pour réaliser les avantages de l’intégration technologique.
Cet article présente un cadre en cinq étapes pour relever ces défis et accélérer la capture de valeur dans les contextes de fusions et acquisitions. Ce cadre garantira que votre stratégie de données post-fusion avec Cloudera offre les capacités nécessaires pour rationaliser le processus d'intégration technologique.
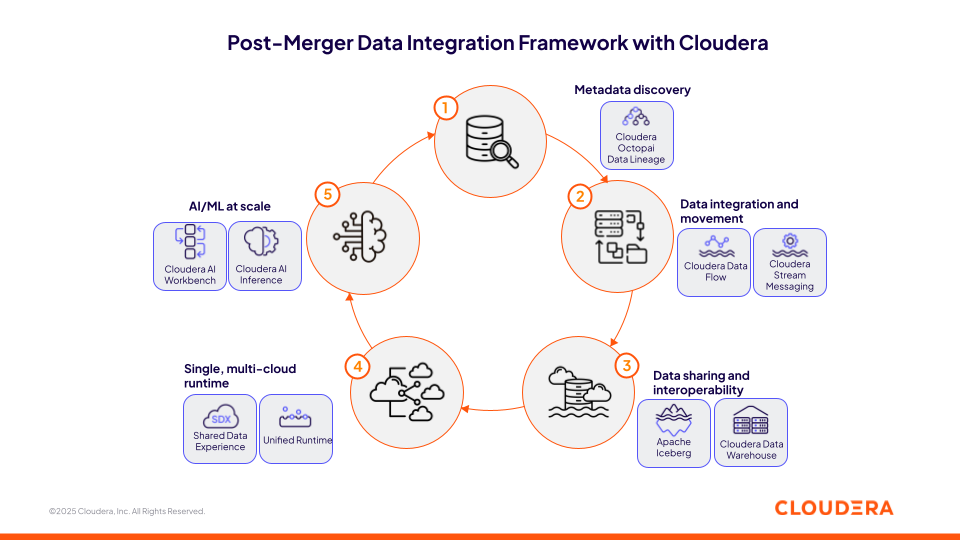
Figure 1 : Cadre d'intégration des données avec Cloudera après la fusion
1. Accélérez l'intégration post-fusion avec Cloudera Octopai Data Lineage
Au début de l'intégration post-fusion, la phase de découverte des données devient souvent un goulot d'étranglement, car les sources fragmentées et non documentées retardent les efforts critiques d'analyse et de conformité. Cloudera Octopai Data Lineage répond à ce défi en proposant une solution automatisée de gestion des métadonnées alimentée par l’IA, qui accélère la découverte de données, la traçabilité de bout en bout et le catalogage à travers des environnements hybrides et multi-cloud complexes.
Cloudera Octopai Data Lineage cartographie efficacement les data flow et comble les lacunes des métadonnées, fournissant une lignée multidimensionnelle qui retrace les origines et les transformations pour une visibilité complète. Avec plus de 60 intégrations natives et des connecteurs universels pour les systèmes non natifs, Cloudera Octopai Data Lineage simplifie l’intégration des domaines de données acquis, améliorant ainsi la transparence, la qualité et la confiance dans les données.
Par exemple, dans les scénarios de fusion bancaire, cette capacité facilite l’identification rapide et le marquage des ensembles de données liés aux risques, garantissant la conformité aux normes réglementaires telles que BCBS 239, tout en réduisant le besoin d’audits manuels ou d’interventions approfondies.
2. Intégrez des sources de données disparates avec Cloudera données en mouvement
L'intégration de sources de données diverses et l'élimination des pipelines ETL complexes et personnalisés constituent un défi critique après une fusion. Cloudera offre des capacités robustes pour l’ingestion de données en batch et en temps réel, le traitement et la distribution des données via Cloudera Data Flow (propulsé par Apache NiFi) et Cloudera Streaming (propulsé par Apache Kafka et Apache Flink).
Avec plus de 450 connecteurs, Cloudera Data Flow fournit une interface visuelle glisser-déposer pour ingérer des données à partir d'une variété de sources de données hétérogènes, que ce soit sur site, dans les clouds ou à la périphérie (ou edge computing). De plus, Cloudera Streaming fournit une architecture de bus de messagerie qui découple les systèmes sources des systèmes consommateurs entre les deux entités, éliminant ainsi les intégrations point à point qui ajoutent de la complexité architecturale et des coûts plus élevés.
Lors de l’intégration post-fusion, ces capacités peuvent considérablement accélérer et simplifier le transfert des données entre organisations. Par exemple, Cloudera Data Flow peut être utilisé pour intégrer rapidement les données sur site provenant des systèmes sources hérités de l’entreprise acquise dans le Data Warehouse cloud-native de la société mère, accélérant ainsi la prise de décision.
3. Créez une couche de partage de données sécurisée sur le Data Lakehouse ouvert de Cloudera avec Apache Iceberg
Le partage de données entre les entités en fusion est une exigence essentielle pour une prise de décision intégrée et pour tirer des enseignements. Ce processus peut être complexe en raison de la diversité des technologies d’analytique exploratoire et de veille stratégique, ainsi que des modèles variés de sécurité des données utilisés par différents systèmes.
Une approche open data lakehouse qui combine Apache Iceberg, le Cloudera Iceberg REST Catalog et Cloudera Shared Data Experience (SDX) permet aux organisations de développer une couche de partage de données unifiée. Cette couche est compatible avec divers moteurs analytiques (par exemple, Snowflake, Databricks, AWS EMR, AWS Athena et Salesforce Data Cloud, tant que ces moteurs sont activés pour Iceberg REST Catalog) et fournit un modèle de sécurité et de gouvernance finement granulaire pour gérer l'accès à un large éventail d'utilisateurs, y compris les équipes de data science nouvellement intégrées.
Par exemple, deux organisations de santé impliquées dans la fabrication de médicaments peuvent utiliser Cloudera pour construire un datapool conforme à GxP , qui consolide les actifs de données des entités fusionnant tout en assurant le respect des exigences réglementaires.
4. Standardiser les initiatives interenvironnementales sur un environnement unique multi-Cloud.
Les différents environnements utilisés pour les activités analytiques dans les deux entités fusionnantes entraînent des opérations en duplication tout au long du cycle de vie des données, incluant plusieurs pipelines d’ingénierie des données pour des tâches courantes telles que l’ingestion de données et la standardisation des données.
Cloudera permet aux organisations de normaliser les opérations de données et d'IA sur un runtime commun dans divers environnements de cloud privé et public. Cette capacité découle du modèle d'infrastructure conteneurisée sous-jacent utilisé dans tous les environnements, d'un mécanisme d'authentification et d'autorisation des utilisateurs cohérent (Cloudera SDX), et de Cloudera Manager, qui sert de tableau de bord unique pour gérer les grappes à travers différents environnements de déploiement et régions.
Dans un contexte post-fusion, cette normalisation est transformatrice : les deux entreprises peuvent intégrer leurs opérations de cycle de vie des données sur un seul runtime, en éliminant les outils redondants et en facilitant le partage des données, des insights et des modèles d'IA. Cela conduit à une réduction des coûts technologiques et de main-d'œuvre pour les opérations de données et le développement de modèles IA/ML, à une augmentation de la productivité des praticiens, à la consolidation de plusieurs outils et à la réduction des silos de données.
5. Développez vos initiatives d'IA où que vous soyez grâce à Cloudera AI
Après l’acquisition ou la fusion, le défi immédiat est d’intégrer les outils, modèles et data scientists disparates issus de la start-up innovante nouvellement acquise, tout en gérant l’évolution des besoins en capacité. Cloudera AI Workbench et AI Inference permettent aux organisations de développer leurs initiatives d’IA sur site ou dans le cloud en :
Fournir une solution de bout en bout basée sur des conteneurs pour l'ingénierie des fonctionnalités, l'entraînement des modèles, le suivi des expérimentations et le déploiement des modèles
Faciliter le partage de modèles d'IA qui permet aux data scientists de collaborer entre équipes disparates
Exploiter les services d'accélération matérielle et logicielle des partenaires Clouder qui peuvent accélérer l'ensemble du cycle de vie de la science des données en améliorant les performances d'ingénierie des données de 20x et les performances d'inférence de l'IA jusqu'à 6x.
Avec Cloudera, l'entreprise intégrée peut réaliser une réduction substantielle des coûts en déplaçant les charges de travail persistantes et à forte intensité de calcul, telles que les modèles d'IA/ML, vers des environnements sur site. Plus important encore, il peut accélérer le délai de commercialisation pour les nouvelles applications d'IA combinées. Cela permet à l'organisation de réaliser rapidement « l'avantage concurrentiel » qu'elle recherchait au départ auprès du M & A
Passez à l'étape suivante pour garantir une intégration réussie après votre prochaine fusion et acquisition
Cloudera peut accélérer l’intégration post-fusion des actifs de données et des capacités analytiques entre les deux entités intégratrices. Notre plateforme offre une évolutivité tout au long du cycle de vie des données, un modèle de déploiement indépendant de l'infrastructure, et une interopérabilité du data lakehouse sur les services Cloudera et Apache Iceberg. Cette combinaison fournit un plan architectural pour standardiser les initiatives d'IA/ML et les opérations de données, et pour fournir un modèle de partage de données qui peut être utilisé à la fois par les services Cloudera et non-Cloudera.
Pour programmer une démonstration ou un tour de produit, contactez notre équipe.
