Exploiter le potentiel de l'IA d'entreprise : la distillation des connaissances pour l'analyse du service client





Les entreprises sont aujourd'hui confrontées à un défi de taille : elles souhaitent tirer parti des modèles d'IA avancés pour rester compétitives, mais doivent maîtriser les coûts élevés des grands modèles de langage (LLM) basés sur le cloud et se conformer aux réglementations en matière de confidentialité des données.
Comment les entreprises peuvent-elles explorer l'IA de pointe sans dépasser leur budget ni exposer des données privées sensibles ? Chez Cloudera, nous avons développé une solution qui fait de ce défi une opportunité : l'utilisation de données synthétiques générées à partir de données privées et de la distillation des connaissances pour créer des systèmes d'IA rentables, précis et conformes.
Dans cet article, nous expliquons comment le Synthetic Data Generation Studio, qui fait partie de Cloudera AI Studios, permet aux organisations de tirer parti des innovations en matière d'IA, même lorsque les données réelles sont rares ou sensibles.
Cas d'utilisation et Points clés à retenir
Cas d'utilisation : à partir d'un cas d'utilisation interne, nous vous montrerons comment nous avons considérablement amélioré les performances et le débit global du pipeline de tickets d'assistance client de Cloudera grâce à la distillation des connaissances à partir de données synthétiques générées à partir de données privées, tout en préservant la confidentialité des données et la conformité réglementaire.
Les points essentiels à retenir :
La confidentialité des données comme avantage concurrentiel : les données synthétiques permettent d'innover sans risque réglementaire.
Des performances rentables : les modèles plus petits et affinés surpassent les alternatives plus grandes et gourmandes en ressources.
Une adaptabilité aux cas d'utilisation : la même approche peut alimenter des cas d'utilisation allant de la détection des fraudes au service client personnalisé.
Défi commercial : équilibrer la vitesse et la précision des modèles d'IA sans compromettre la confidentialité des données
L'équipe du service client de Cloudera exploite des modèles d'IA pour analyser et résumer les tickets d'assistance en temps réel. Le système intègre les commentaires des clients ou des agents du service client Cloudera. Il analyse ensuite chaque commentaire et en extrait un ensemble d'analyses, telles que le sentiment et le résumé. Chez Cloudera, ces analyses sont essentielles pour améliorer l'expérience client.
En raison de la nature sensible des données clients traitées dans ce pipeline, seuls les modèles opérant dans des environnements locaux peuvent être exploités. Par ailleurs, aucune donnée client ne peut être partagée avec des sources externes.
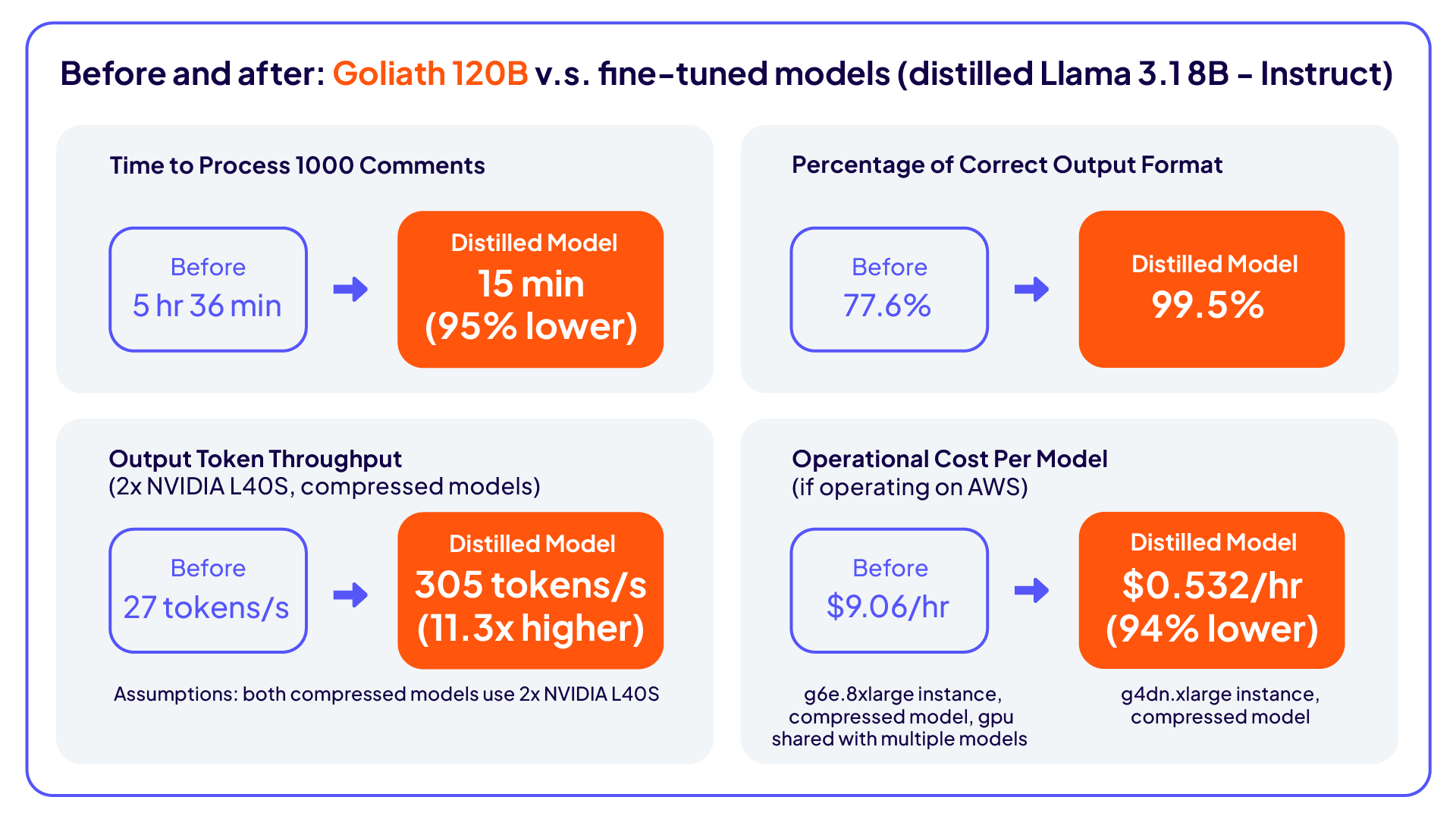
Au départ, l'équipe s'appuyait sur des LLM locaux (Goliath 120B) pour analyser les commentaires. Ceux-ci répondaient aux exigences de performance de base, mais étaient à la traîne en termes de vitesse et de performances de génération : en moyenne, le traitement des demandes prenait 12 à 15 secondes chacune, et les demandes arrivaient toutes les 30 secondes. Le respect des résultats attendus était de 77,5 % et la précision de génération était inférieure à celle des modèles propriétaires, ce qui constituait un obstacle à l'évolutivité et aux performances des LLM.
Les défis liés à l'utilisation de grands LLM locaux (Goliath-120B) étaient évidents : temps de réponse plus lents, coûts accrus, précision de génération inférieure à celle des modèles de pointe basés sur le cloud et risques de non-conformité.
Les grandes entreprises sont confrontées à des compromis similaires : trouver un équilibre entre la précision et la vitesse de l'IA et les risques d'exposition des données.
Solution de Cloudera : distillation des connaissances avec des données privées
L'innovation de Cloudera repose sur une approche de la distillation des connaissances centrée sur la confidentialité.
Au lieu d'entraîner des modèles à partir de données brutes sur les clients, ce qui présentait des risques réglementaires et d'exposition, nous avons généré des ensembles de données synthétiques à l'aide de Cloudera Synthetic Data Studio. Ce nouvel outil low-code de Cloudera AI imitait les interactions du monde réel (questions techniques, scénarios de dépannage, etc.) sans jamais exposer d'informations privées.
La génération d'interactions synthétiques avec le service client présentait des avantages en termes de réglementation et d'exposition, et permettait également à l'équipe d'envoyer les données synthétiques à des LLM de pointe basés sur le cloud afin d'extraire des informations telles que le sentiment des clients à partir des LLM les plus performants. Ces LLM basés sur le cloud offre une extraction d'informations beaucoup plus précise que les grands modèles locaux, ce qui en fait une source idéale pour distiller des informations fiables à partir de ces LLM de pointe.
La solution de données synthétiques de Cloudera a éliminé tout risque de non-conformité et de confidentialité, tout en générant des données synthétiques de la plus haute qualité (supérieure même à celle des grands LLM locaux existants). Cette approche a permis d'extraire les connaissances des modèles de pointe vers de petits LLM et de résoudre le même problème que le Goliath 120B, mais à un coût moindre et avec une plus grande précision.
Notre processus
Génération de données : à l'aide du workflow de génération de données de Synthetic Data Studio, nous avons créé une invite demandant à Claude Sonnet de générer des questions et des réponses de clients. Cette invite demande au LLM de générer des questions et réponses du service client, en impose le ton et détaille la structure. Nous fournissons également une liste de sujets qui apparaissent dans les données réelles (telles que le service client pour Cloudera AI ou Cloudera Data Warehouse) et utilisons des sujets de base pour garantir la génération de tickets d'assistance diversifiés et réalistes.
Réglage fin : en exploitant uniquement les données filtrées, l'équipe a divisé les données en données d'entraînement et de développement testées et a distillé les connaissances du modèle Claude Sonnet vers un modèle Meta Llama3.1-8B-instruct. Elle a mené plusieurs expériences en sélectionnant les paramètres de réglage fin qui maximisent les performances du LLM distillé.
Évaluation : à l'aide du workflow d'évaluation de Synthetic Data Studio, l'équipe a créé une invite pour indiquer à un LLM arbitre comment évaluer la qualité des données générées et filtrer les échantillons de mauvaise qualité.
Grâce aux évaluations humaines et celles automatisées du LLM arbitre, l'équipe de Cloudera a noté les questions et réponses réelles des tickets du service client. Elle s'est concentrée sur les réponses qui différaient entre les LLM déployés et distillés et a rapporté le taux de réussite de chaque LLM. Elle a également mesuré les améliorations en termes de vitesse, de respect des résultats attendus et de coût de déploiement du modèle.
Les Résultats
Amélioration de la vitesse : le temps de traitement a diminué de 95 %.
Meilleure structure de sortie : le respect des résultats est passé de 77,5 % à 99,5 %.
Précision accrue du LLM : en comparant le LLM distillé plus petit (Llama 3.1 8B) au LLM Goliath déployé (Goliath 120B), le taux de réussite était de 70 % contre 30 % lorsque Phi-4 était utilisé comme arbitre et de 63 % contre 37 % lorsque des évaluateurs humains comparaient les deux modèles.
Amélioration des coûts et de l'efficacité : le LLM distillé plus petit a réduit les besoins en calcul et en mémoire tout en augmentant l'évolutivité en temps réel et en préservant la confidentialité des données. Le débit a été multiplié par 11.
Les résultats sont évidents : les entreprises peuvent atteindre l'excellence en matière d'IA sans compromettre la confidentialité des données. En synthétisant les données d'entraînement et en distillant les connaissances, elles évitent les compromis entre innovation et conformité.
Les données synthétiques permettent l'innovation sans risque réglementaire
En développant une approche de distillation des connaissances, Cloudera a réduit le temps de traitement de 95 %, augmenté la conformité de la structure de sortie à 99,5 % et déployé un modèle Llama 3.1 8B distillé qui a surpassé le modèle Goliath 120B précédent de 70 % en termes de précision (selon Phi-4) et de 63 % en termes d'évaluations humaines.
Cette méthode a éliminé les risques de non-conformité en évitant l'utilisation directe de données sensibles et a également permis d'obtenir un débit 11 fois supérieur, démontrant que des modèles plus petits et mieux affinés peuvent surpasser les alternatives plus grandes et gourmandes en ressources, tant en termes de vitesse que de précision.
Essayez notre AMP pour découvrir comment exploiter des données synthétiques privées afin de distiller les connaissances d'un grand modèle vers un modèle plus petit pour un cas d'utilisation dans le domaine du service client.