
Construire des applications RAG - Le diable est dans les détails
La création d'applications de génération augmentée par récupération (RAG) peut rapidement devenir complexe, nécessitant une gestion minutieuse de l'ingestion de données, du traitement et de la récupération des données. Traditionnellement, les développeurs ont navigué à travers les étapes du découpage des données, de l'insertion d'embeddings et de l'intégration de bases de données vectorielles.
Cependant, l'un des pièges les plus courants lors de la mise en œuvre d'une solution RAG est de ne pas comprendre comment ces composants sont interdépendants. Les développeurs devraient se poser la question suivante : « Nos données peuvent-elles être découpées telles quelles, ou devons-nous les affiner avant de les découper ? »
Cloudera Data Flow et les processeurs exclusifs RAG Pipeline de Cloudera simplifient le processus complexe d'affinement des données non structurées par le biais du partitionnement, permettant un découpage plus efficace et des embeddings vectoriels de meilleure qualité. Bien qu'un partitionnement ou un découpage mal conçus puissent nuire aux performances et à la qualité de l'intégration, les outils de Cloudera abstraient une grande partie de cette complexité, rationalisant ainsi le développement de solutions RAG efficaces et fiables.
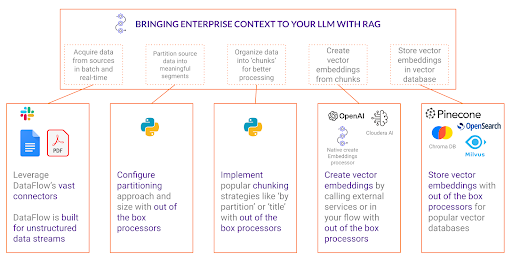
Explorons les étapes critiques d'un flux de travail RAG—partitionnement, segmentation, intégration et insertion—et montrons comment la technologie de Cloudera simplifie chaque étape.
Répartition des données : la fondation de RAG
La première étape essentielle d’un flux de travail RAG est le partitionnement. Ce processus consiste à décomposer des sources de données volumineuses et parfois non structurées en segments significatifs, ce qui permet une itération programmatique sur des données non structurées. Bien sûr, le processus de récupération est toujours possible sans partitionnement, mais plus vous avez de contrôle granulaire sur votre traitement, plus vous aurez de flexibilité pour créer des flux pour différentes sources de données. La répartition garantit que les données sont structurées en parties gérables qui s’alignent sur la façon dont les utilisateurs interrogent les informations.
Les stratégies de répartition varient en fonction de la nature des données. Par exemple, la répartition par en-têtes de section permet une récupération plus organisée lors du traitement de documents longs tels que des manuels d'utilisation. En revanche, la répartition peut impliquer de diviser le contenu selon les horodatages pour préserver le flux conversationnel des données telles que les journaux de discussion. Une autre considération clé concerne les limites de jetons — étant donné que la plupart des modèles d'intégration ont une taille de jeton prédéfinie pouvant être traitée simultanément, la répartition doit s'aligner sur ces contraintes pour garantir des performances optimales.
Une approche de répartition bien définie permet de maintenir la précision, l'efficacité et la convivialité des applications RAG. Les développeurs peuvent optimiser la qualité des réponses en veillant à ce que seules les données les plus pertinentes soient récupérées et transmises au LLM, tout en réduisant au minimum la surcharge de calcul inutile.
Découpage : garantir la préservation du contexte
Une fois la répartition terminée, l'étape suivante est le découpage. Le découpage en blocs consiste à regrouper des répartitions liées afin de conserver un contexte significatif. Alors que la répartition divise le contenu en composants fondamentaux, le découpage garantit que ces composants conservent leurs relations, évitant ainsi la perte de contexte.
Par exemple, une clause ou un règlement peut s'étendre sur plusieurs paragraphes dans des documents juridiques. Si ces éléments sont répartis de manière trop étroite, le sens peut être perdu lors de la récupération de contenu en fonction de la requête d’un utilisateur. Le découpage aide à regrouper des segments de texte apparentés en une unité logiquement complète. Ceci garantit que lorsqu'un utilisateur émet une requête, le modèle reçoit suffisamment d'informations contextuelles pour générer une réponse précise et pertinente.
Les stratégies de découpage varient en fonction de la nature de l'ensemble de données. Certaines approches impliquent un simple découpage en morceaux de longueur fixe, où les segments sont regroupés sur la base d'un nombre prédéfini de jetons. Des stratégies plus avancées peuvent impliquer de segmenter le titre d’un document avec le texte connexe.
Un découpage efficace améliore la précision de la recherche, optimise la latence de récupération et garantit que les réponses générées par les LLM sont contextuellement pertinentes et précises. De plus, en déterminant une stratégie de découpage qui maximise la préservation du contexte, vous pouvez éclairer la décision de votre modèle d'intégration avec la connaissance prédéterminée de la taille de vos segments.
Intégration : transformation du texte en vecteurs consultables
Une fois les segments bien structurés en place, l'étape suivante du flux de travail RAG est l'intégration. Les embeddings sont des représentations numériques de texte permettant aux machines de comprendre et de comparer la signification sémantique de différents segments de texte. Sans l'intégration, les applications RAG seraient limitées à de simples recherches par mots-clés, qui manquent de la compréhension contextuelle d'une véritable recherche sémantique.
L'intégration est un processus en plusieurs étapes qui comprend la tokenisation, la transformation vectorielle et le stockage. Lorsqu'un segment de texte passe par un modèle d'embedding, il est d'abord décomposé en tokens. Ces tokens sont ensuite convertis en un vecteur de haute dimension qui capture l'essence du texte dans un format adapté aux recherches mathématiques de similarité telles que la distance euclidienne (L2) et la similarité cosinus.
Il est très important de choisir le bon modèle d'intégration. Certains modèles sont optimisés pour la récupération à usage général, tandis que d'autres sont ajustés pour des applications spécifiques à un domaine, telles que les documents juridiques, médicaux ou techniques. Un autre aspect clé est la dimensionnalité des vecteurs, qui doit correspondre au schéma de la base de données vectorielle. Un décalage dans la taille du vecteur peut entraîner des recherches inefficaces ou des problèmes de compatibilité.
Une fois que les segments de texte sont intégrés dans des représentations vectorielles, ils deviennent consultables à l'aide de mesures de similarité. Cela permet de récupérer très efficacement le contenu le plus pertinent en fonction des requêtes des utilisateurs, améliorant ainsi considérablement la précision et la réactivité des applications alimentées par RAG.
Cloudera Data Flow propose un processeur d’intégration incroyablement puissant mais facile à utiliser qui fait évoluer les capacités de vos data flows, vous permettant ainsi de tirer parti d’un modèle dans le contexte du processeur. Il n'est pas nécessaire d'appeler une API (aucun GPU requis). Le processeur a trois propriétés simples :
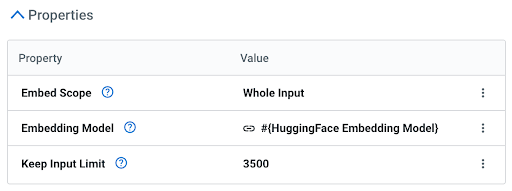
Ceci vous donne le contrôle granulaire pour choisir le meilleur modèle d'intégration pour chaque data flow.
Insertion des morceaux intégrés dans une base de données vectorielle : permettre une récupération efficace.
La dernière étape du flux de travail RAG consiste à insérer les segments intégrés dans une base de données vectorielle. Les bases de données vectorielles sont conçues pour effectuer des recherches de similarité à grande vitesse, permettant ainsi la récupération efficace de contenu pertinent lorsqu'un utilisateur soumet une requête.
Contrairement aux bases de données traditionnelles qui reposent sur une indexation structurée pour des correspondances exactes, les bases de données vectorielles utilisent des recherches de similarité et des algorithmes tels que ANN et KNN pour trouver des embeddings qui correspondent étroitement à la requête de l'utilisateur. C'est ce qui permet aux applications RAG de récupérer un contenu sémantiquement pertinent, même si le libellé de la requête diffère du texte stocké.
Une fois que les données intégrées sont insérées dans la base de données vectorielle, le système est prêt pour des requêtes en temps réel. Lorsqu'un utilisateur soumet une requête, celle-ci est transformée en un vecteur d'embedding, comparée aux vecteurs stockés, et les résultats les plus pertinents sont récupérés, formant ainsi la base de la réponse du LLM.
Cloudera Data Flow propose de nombreux processeurs de connexion VectorDB tels que Milvus, Pinecone et Chroma, avec d'autres à venir.
Simplifiez le développement de vos applications RAG dès aujourd'hui
Avec Cloudera Data Flow et ses processeurs RAG Pipeline spécialisés, les organisations peuvent désormais créer, déployer et optimiser des applications RAG avec une facilité sans précédent. En simplifiant une grande partie de la complexité technique, les solutions de Cloudera permettent aux développeurs de se concentrer sur l'amélioration de la précision de la récupération, l'optimisation de la génération de réponses et l'amélioration de l'expérience utilisateur globale.
Les entreprises peuvent rapidement mettre en œuvre des solutions RAG qui évoluent efficacement et fournissent des réponses précises et contextuelles en tirant parti des processeurs exclusifs de partitionnement, de découpage, d'intégration et d'intégration VectorDB de Cloudera.
Si vous souhaitez savoir comment Cloudera peut vous aider à rationaliser le développement de vos applications RAG, contactez notre équipe pour une démonstration ou consultez notre documentation technique pour plus d'informations.
Restez à l'écoute pour une prochaine plongée approfondie dans les techniques avancées d'optimisation RAG !
En savoir plus :
Pour découvrir les nouvelles fonctionnalités de Cloudera Data Flow 2.9 et en savoir plus sur la manière dont la solution peut transformer vos pipelines de données, regardez cette vidéo.
