Écosystème d'Apache Hadoop
Hadoop est un écosystème d'éléments en open source qui change fondamentalement la manière dont les entreprises stockent, traitent et analysent les données. Contrairement aux systèmes traditionnels, Hadoop permet l'exécution de plusieurs types de charges de travail analytiques sur les mêmes données, au même moment, à très grande échelle, sur du matériel industriel. CDH, la plate-forme en open source de Cloudera, est la distribution la plus connue d'Hadoop et de ses projets connexes dans le monde (avec une assistance disponible via l'inscription à Cloudera Enterprise).
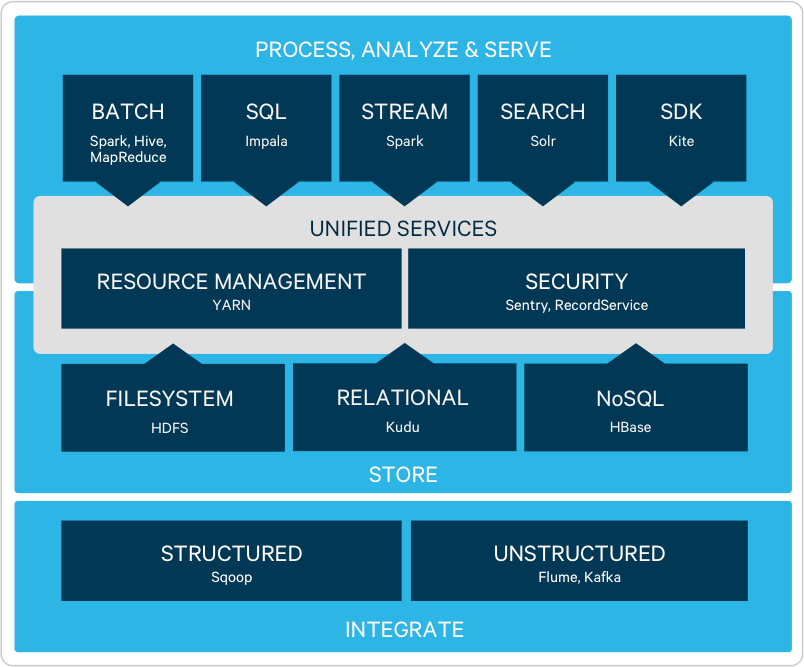
Stocker
L'architecture flexible et infiniment évolutive d'Hadoop (basée sur le fichier système HDFS) permet aux organisations de stocker et analyser des quantités et types illimités de données—dans une plate-forme unique en open source sur du matériel industriel.


Traitement
Intégrer rapidement aux applications et systèmes existants pour déplacer les données vers et hors Hadoop à travers un traitement de chargement massif (Apache Sqoop) ou un chargement en continu (Apache Flume, Apache Kafka).
Transformer des données complexes, à grande échelle, avec de multiples options d'accès aux données (Apache Hive, Apache Pig) pour un traitement par lots (MR2) ou à intégration rapide (Apache Spark™). Traiter des données de flux alors qu'elles arrivent dans votre cluster via Spark Streaming.
Découvrir
Les analystes interagissent en permanence avec des données totalement fidèles avec Apache Impala, la entrepôts de données d'Hadoop. Avec Impala, les analystes font l'expérience d'une performance SQL et de fonctionnalités de qualité BI et découvrent la compatibilité avec tous les meilleurs outils de BI.
Avec Cloudera Search, une intégration d'Hadoop et d'Apache Solr, les analystes peuvent accélérer le processus de découverte des tendances des données de toutes quantités et tous formats, en particulier si combiné avec Impala.


Modéliser
Avec Hadoop, les analystes et data scientistes ont la flexibilité de développer et d'itérer des modèles statistiques avancés à l'aide d'une combinaison de technologies partenaires et de systèmes en open source comme Apache Spark™.
Disponibilité
Le système de fichiers distribué pour Hadoop, Apache HBase, supporte les lectures/écritures aléatoires et rapides (« données rapides ») des applications en ligne.

CDH : construite en open source et standards ouverts
CDH, la distribution d'Hadoop la plus connue dans le monde, est la plate-forme 100% open source de Cloudera. Elle inclut tous les éléments majeurs de l'écosystème d'Hadoop pour stocker, traiter, découvrir, modéliser et servir des données illimitées, et est conçue pour satisfaire les meilleurs standards de stabilité et fiabilité de l'entreprise.
CDH est entièrement basée sur des standards ouverts pour une architecture à long terme. En tant que principale programmatrice de standards ouverts dans Hadoop, Cloudera détient le palmarès des nouvelles solutions en open source de sa plate-forme (comme Apache Spark™, Apache HBase et Apache Parquet) qui sont finalement adoptées par tout l'écosystème.
En savoir plus sur les éléments clés de CDH
