Apache Tez
Framework pour les applications YARN de traitement des données dans Hadoop
Apache™ Tez est un framework extensible conçu pour le développement d'applications dédiées au traitement de données interactif et haute performance par lots, coordonné par YARN dans l'écosystème Apache Hadoop. Tez vient améliorer le paradigme MapReduce en le dotant d'une vitesse bien plus élevée, tout en conservant sa capacité à gérer des quantités de données de l'ordre du pétaoctet. Certains projets phares de l'écosystème Hadoop, comme Apache Hive et Apache Pig, font appel à Apache Tez, tout comme un nombre croissant d'applications d'accès aux données tierces, développées pour l'écosystème Hadoop élargi.
Hive et Tez
En tant que norme de facto pour SQL-In-Hadoop, Apache Hive est idéal pour traiter les requêtes interactives et par lots à l'échelle du pétaoctet. Hive intègre Tez afin de transformer les déclarations SQL complexes en graphiques de traitement de données hautement optimisés et sur mesure offrant un équilibre parfait entre performance, débit et évolutivité. Les innovations Apache Tez sont à l'origine des nombreuses améliorations de performances du projet Hive portées par l'Initiative Stinger, un vaste effort de la communauté incluant les contributions de quelque 145 ingénieurs venus de 44 entreprises différentes. On peut donc dire que Tez aide Hive à devenir interactif.

Objectif de Tez
Apache Tez fournit une API développeur ainsi qu'un framework pour la conception d'applications YARN natives qui comblent le fossé entre les tâches interactives et par lots. Ces applications d'accès aux données peuvent ainsi gérer des pétaoctets de données sur des milliers de nœuds. La bibliothèque de composants Apache Tez permet aux développeurs de créer des applications Hadoop qui s'intègrent nativement à Apache Hadoop YARN et obtiennent de bonnes performances dans les clusters gérant des charges de travail mixtes. En raison de ses capacités d'extension et d'intégration, Tez fournit une liberté sur mesure pour représenter des applications de traitement de données hautement optimisées ; celles-ci bénéficient ainsi d'un avantage par rapport aux moteurs orientés utilisateur final, comme MapReduce ou Apache Spark. Ce framework offre également une architecture d'exécution personnalisable, grâce à laquelle les utilisateurs peuvent représenter des calculs complexes sous forme de graphiques de dataflow. Ils peuvent ainsi optimiser leur performance de manière dynamique à l'aide d'informations concrètes à propos des données et des ressources nécessaires pour les traiter.
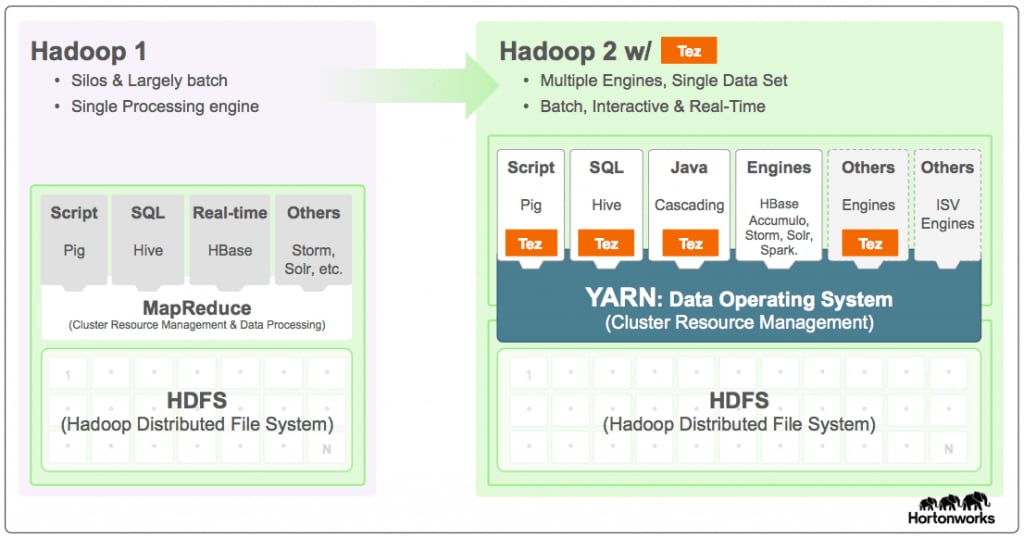
Fonctionnement de Tez
L'amélioration du traitement des données dans Hadoop proposée par Apache Tez dépasse de loin les avantages offerts par Apache Hive et Apache Pig. Ce projet a établi la norme en matière d'intégration avec YARN pour les charges de travail interactives. Parcourez les descriptions suivantes pour découvrir comment Apache Tez réalise ses tâches principales.
Représentation, modélisation et exécution d'une logique de traitement
Tez modélise le traitement des données sous forme de graphique représentant le flux de données, où les sommets représentent la logique d'application et les liens le mouvement des données Une API de définition du dataflow riche permet aux utilisateurs de représenter des requêtes complexes. L'API s'intègre bien aux plans de requête générés par des applications déclaratives de niveau supérieur comme Apache Hive et Apache Pig.
Modélisation de l'interaction entre modules d'entrée, de traitement et de sortie
Pour façonner la logique utilisateur de chaque sommet du graphique de dataflow, Tez utilise un ensemble de modules d'entrée, de traitement et de sortie. L'entrée et la sortie déterminent le format des données, ainsi que la façon et l'emplacement de leur lecture ou leur écriture. Le traitement gère la logique de transformation des données. Tez n'impose aucun format de donnée : la seule règle imposée est la compatibilité des formats d'entrée, de traitement et de sortie.
Reconfiguration dynamique des graphiques
Le traitement distribué de données est dynamique ; il est donc difficile de déterminer à l'avance les méthodes idéales de mouvement des données. Lors de l'exécution, la disponibilité des informations augmente, ce qui peut aider à optimiser encore davantage le plan d'exécution. C'est pourquoi Tez inclut une prise en charge des modules enfichables de gestion des sommets : elle permet la collecte d'informations sur l'exécution et la modification dynamique des graphiques de dataflow, le tout afin d'optimiser la performance et l'utilisation des ressources.
Optimisation de la performance et de la gestion des ressources
YARN gère les ressources dans un cluster Hadoop en fonction de la capacité et du chargement du cluster. Le framework du moteur d'exécution Tez acquiert des ressources à partir de YARN et réutilise chaque composant dans le pipeline, afin qu'aucune opération ne soit inutilement dupliquée.
API pour la définition de graphes orientés acycliques (DAG)
Tez possède une API Java simple qui permet de représenter les traitement de données sous forme de DAG. L'API se divise en trois composants :
- DAG – il définit la tâche globale. L'utilisateur crée un DAG pour chaque tâche de traitement de données.
- Sommet – il définit la logique utilisateur ainsi que les ressources et l'environnement nécessaire pour exécuter la logique utilisateur. L'utilisateur crée un sommet pour chaque étape de la tâche et l'ajoute au DAG.
- Segment – il représente le lien entre les sommets producteur et consommateur. L'utilisateur crée un segment pour connecter les sommets producteur et consommateur.
Réutilisation des containers
Tez suit le modèle Hadoop traditionnel : chaque tâche est divisée en tâches individuelles, elles-mêmes exécutées comme processus via YARN, au nom de l'utilisateur. Ce modèle s'accompagne des coûts inhérents au démarrage et à l'initialisation d'un processus, la gestion des retards et l'attribution de chaque container via le gestionnaire de ressources YARN.