Plateforme Cloudera
Intégrez l'IA à vos données, où qu'elles se trouvent : libérez le potentiel des données dans le cloud, dans les centres de données et en périphérie.

Vue d'ensemble
Flexibilité optimale en matière de gestion des données, d'analyse et d'IA.
La plateforme Cloudera offre une expérience cohérente, une gouvernance unifiée et un contrôle élastique dans n'importe quel environnement : sur site, dans le cloud public et en périphérie.
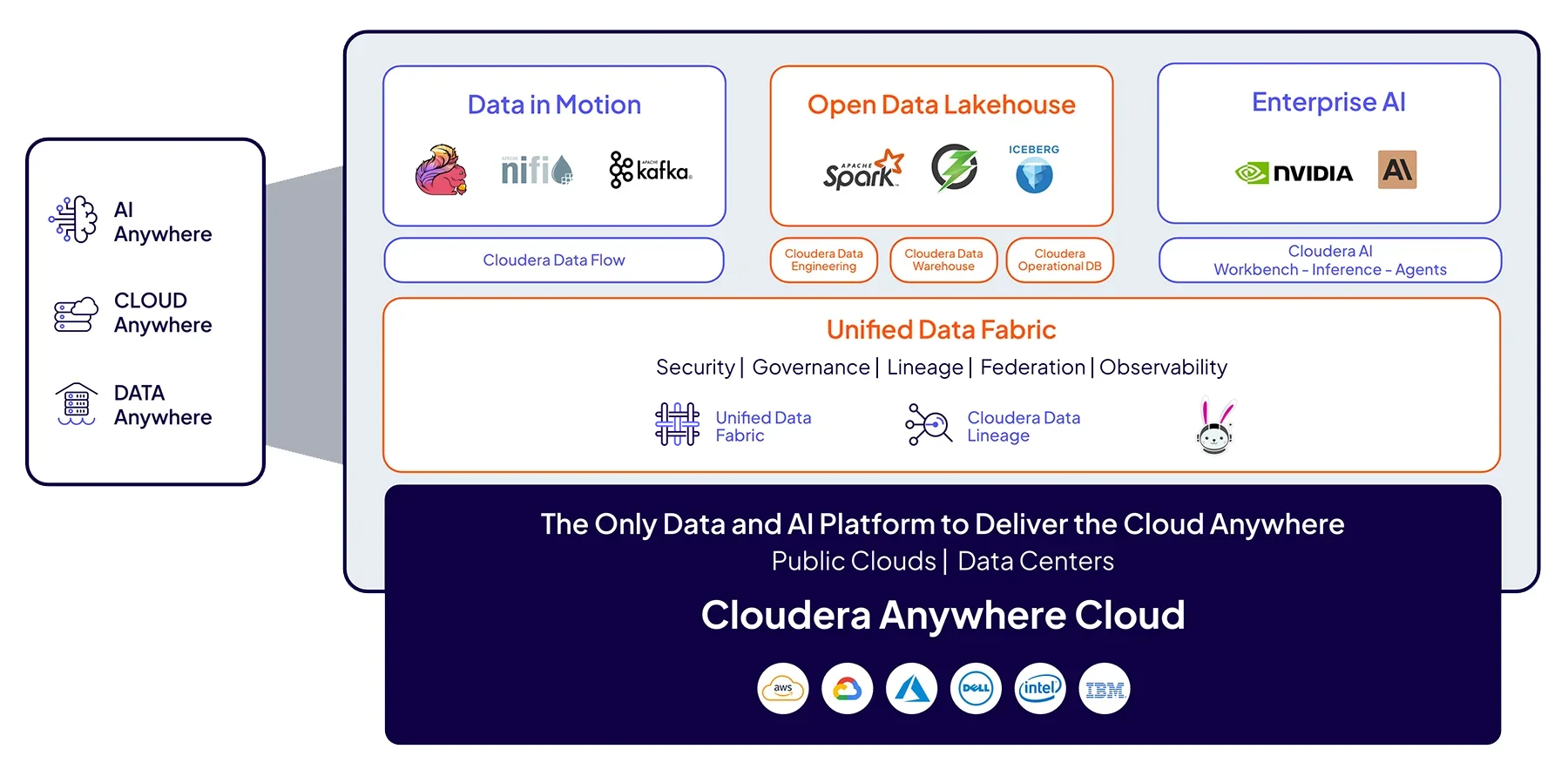
Expérience cohérente
L'accès à des services, des API et des interfaces utilisateur identiques dans tous les centres de données et tous les clouds permet aux équipes de changer d'environnement sans avoir à suivre de nouvelle formation ni à se rééquiper.
Flexibilité hybride
Gérez les pics de demande en transférant vos données vers le cloud tout en les conservant de manière sécurisée sur site, sans aucune migration nécessaire.
Gouvernance unifiée
Appliquez des politiques cohérentes en matière de sécurité, de traçabilité et d'audit dans tous les environnements, afin de garantir la conformité, où que se trouvent les données.
CAS D'UTILISATION
Alimentez les cas d'utilisation des données et de l'IA, de la périphérie au cloud.
Les plus grandes entreprises mondiales font confiance à Cloudera pour dégager des informations qui améliorent leurs résultats, les protègent contre les menaces et sauvent des vies.
-
Offrir une expérience cloud cohérente
Développez une seule fois et exécutez partout sur une seule plateforme.
-
Accélérer l'IA d'entreprise
Entraînez et déployez des modèles d'IA en toute sécurité dans les environnements cloud et sur site.
Découvrir comment la banque OCBC s'est transformée grâce à l'IA
-
Construire un data lakehouse ouvert
Consolidez les données structurées et non structurées dans un seul data lakehouse ouvert.
-
Analyses de flux et IoT
Traitez et analysez les données en temps réel, de la périphérie au cloud.
-
Offrir une expérience cloud cohérente
Développez une seule fois et exécutez partout sur une seule plateforme.
-
Accélérer l'IA d'entreprise
Entraînez et déployez des modèles d'IA en toute sécurité dans les environnements cloud et sur site.
Découvrir comment la banque OCBC s'est transformée grâce à l'IA
-
Construire un data lakehouse ouvert
Consolidez les données structurées et non structurées dans un seul data lakehouse ouvert.
-
Analyses de flux et IoT
Traitez et analysez les données en temps réel, de la périphérie au cloud.

Développez, migrez et exécutez des charges de travail dans votre centre de données et dans le cloud.
Une plateforme de données de santé fonctionne partout grâce à notre plateforme hybride sécurisée, qui s'intègre parfaitement à l'environnement de n'importe quel client.

Créez, entraînez et servez des charges de travail d'IA partout, grâce au MLOps et à la gouvernance intégrés.
Une banque internationale augmente la productivité de ses développeurs de 20 % et réduit le recours à son centre d'appels de 10 % grâce à notre plateforme d'IA.

Utilisez la veille stratégique, le SQL et le machine learning sur des tables Apache Iceberg unifiées dans des environnements hybrides.
Unifiez les capacités des entrepôts de données et des lacs de données pour prendre en charge l'IA, la veille stratégique et le machine learning sur une seule plateforme ouverte.

Obtenez des informations instantanées à partir des appareils IoT et des flux d'événements.
Une entreprise de communication mondiale offre des expériences hyper-personnalisées à des millions de personnes, améliorant la satisfaction des clients et réduisant les coûts.
Caractéristiques principales de Cloudera
Exécutez des applications de manière identique sur site ou dans le cloud sans modifier le code. Ce moteur unifié offre une capacité de cloud bursting transparente, vous permettant de déplacer instantanément les charges de travail pour répondre à la demande.
Accédez à des services de données conteneurisés de bout en bout sur une seule plateforme. Ingérez, concevez, stockez et exécutez des charges de travail d'IA et de ML sans prolifération d'outils, ce qui simplifie les pipelines et accélère la génération d'informations.
Cloudera Shared Data Experience (SDX) applique des politiques cohérentes en matière de sécurité, de conformité et de traçabilité des données dans les environnements cloud et sur site, vous offrant un contrôle centralisé sans compromis sur les performances.
Basée sur des normes ouvertes telles qu'Apache Iceberg et Kubernetes, la plateforme s'adapte de manière élastique aux environnements cloud et sur site afin de répondre à la demande croissante en matière de données et d'IA, sans enfermement propriétaire.
CLIENTS
Les grandes entreprises font confiance à Cloudera pour mettre l'IA au service de leurs données, où qu'elles se trouvent.
Les capacités de cloud hybride de Cloudera permettent à MDClone de s'intégrer de manière transparente dans n'importe quel environnement en garantissant la sécurité des données. Ainsi, nous sommes en mesure de proposer notre plateforme révolutionnaire à un large éventail d'organismes de recherche et de professionnels de santé.
 Technologie
AM BITS
Technologie
AM BITS
 Secteur public
CDC
Secteur public
CDC
 Services financiers
Axis Bank
Services financiers
Axis Bank
Écosystème de partenaires ouvert
Notre vaste écosystème de partenaires technologiques complète notre plateforme ouverte, vous offrant la liberté de choisir les outils adaptés et d'accélérer l'innovation partout.
Pour aller plus loin
Passez à l'étape suivante
Si vous souhaitez en savoir plus, notre documentation complète et nos formations libres correspondent parfaitement aux besoins des professionnels des données.
Documentation Cloudera
Consultez les informations techniques détaillées, les guides de démarrage rapide et les notes de mise à jour de la plateforme Cloudera.
Formation gratuite
Accédez à une large gamme de cours et de formations libres pour vous accompagner dans le développement de vos compétences.
Découvrez d'autres produits
Bénéficiez de l'agilité du cloud pour vos données et applications d'IA, où que vous soyez, grâce à de puissants services qui accélèrent l'innovation.
Accélérez la prise de décision basée sur les données, de la recherche à la production, grâce à une plateforme sécurisée, évolutive, ouverte et dédiée à l'IA d'entreprise.
Récupérez vos données de n'importe quelle source et déplacez-les vers n'importe quelle destination de manière simple, sécurisée, évolutive et rentable.
Créez, orchestrez et gérez des pipelines de données d'entreprise en toute sécurité avec Apache Spark sur Iceberg.
Analysez des quantités colossales de données fournies simultanément à des milliers d'utilisateurs, sans compromis sur les coûts, la vitesse ou la sécurité.
Gérez et comprenez la traçabilité des données et les métadonnées pour une visibilité complète dans des environnements hybrides complexes.