Apache Storm
Système pour le traitement en temps réel des données en flux
Grâce à Apache Storm, Hadoop pour les entreprises dispose de fonctionnalités de traitement fiable des données en temps réel. Sur YARN, Storm est très utile pour les scénarios nécessitant des analyses en temps réel, le machine learning et le suivi continu des opérations.
Storm s'intègre à YARN via Apache Slider, tandis que YARN gère Storm ainsi que les ressources de clusters pour les composants liés à la gouvernance des données, la sécurité et les opérations d'une architecture de données moderne.

Objectif de Storm
Storm est un système en temps réel distribué dédié au traitement de volumes importants de données à grande vitesse. Extrêmement rapide, Storm a la capacité de traiter plus d'un million de dossiers par seconde et par nœud dans un cluster de petite taille. Les entreprises exploitent cette vitesse et l'associent avec d'autres applications d'accès aux données dans Hadoop afin d'éviter les événements indésirables ou d'optimiser les résultats positifs.
Cet outil offre de nouvelles opportunités commerciales spécifiques, dont la gestion du service client en temps réel, la monétisation des données, les tableaux de bord opérationnels ou l'analyse de la cybersécurité et la détection de menaces.
Voici quelques cas d'utilisation typique de « prévention » et d'« optimisation » grâce à Storm.
| "Prevent" Use Cases | "Optimize" Use Cases | |
|---|---|---|
| Financial Services |
|
|
| Telecom |
|
|
| Retail |
|
|
| Manufacturing |
|
|
| Transportation |
|
|
| Web |
|
|
Storm est simple, ce qui permet aux développeurs de créer des topologies à l'aide de n'importe quel langage de programmation. Storm rassemble cinq caractéristiques lui permettant de prendre en charge le traitement des données en temps réel. Les voici :
- Rapidité – un million de message de 100 octets traités chaque seconde par nœud
- Évolutivité – une base de calculs parallèles qui fonctionne sur un cluster de machines
- Tolérance aux pannes - quand les workers tombent en panne, Storm les redémarre automatiquement. En cas d'indisponibilité d'un nœud, le worker sera redémarré sur un autre nœud.
- Fiabilité – Storm garantit que chaque tuple, ou unité de données, sera traité au moins une fois, ou une seule fois. Les messages ne sont rejoués qu'en cas d'échec.
- Prise en main facile – les configurations standards permettent la production dès le premier jour. Une fois son déploiement effectué, Storm est simple à utiliser.
Fonctionnement de Storm
Un cluster Storm se divise en trois types de nœud :
- Nœud Nimbus (ou nœud maître, similaire à Hadoop JobTracker) :
- Charge les calculs pour exécution
- Distribue le code dans tout le cluster
- Gère le lancement des workers dans le cluster
- Effectue le suivi des calculs et réaffecte les workers au besoin
- Nœuds ZooKeeper – coordonnent le cluster Storm
- Nœuds Supervisor – communiquent avec les Nimbus par le biais de Zookeeper, démarrent et arrêtent les workers en fonction des signaux envoyés par Nimbus

Le traitement des données par Storm est assuré par cinq niveaux d'abstraction clés :
- Tuples– des listes d'éléments ordonnés. Par exemple, un quadruple peut correspondre à (7, 1, 3, 7)
- Flux – une suite illimitée de tuples.
- Spouts – des sources de flux dans un calcul (par ex. une API Twitter)
- Bolts – des éléments chargés de traiter des flux d'entrée et de produire des flux de sortie. Ils peuvent : exécuter une fonction ; filtrer, agréger ou relier des données ; ou interagir avec les bases de données.
- Topologies – le calcul global, représenté visuellement sous la forme d'un réseau de spouts et de bolts (voir diagramme suivant)
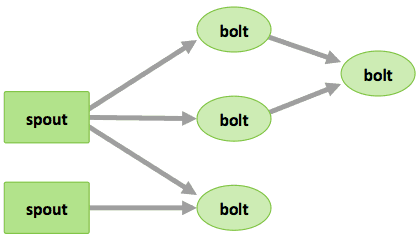
Les utilisateurs de Storm définissent des topologies dédiées au traitement des données au moment du streaming depuis le spout. Lors de l'envoi des données, celles-ci sont traitées et le résultat est ensuite transmis à Hadoop. Suivez le lien pour découvrir le travail de la communauté sur l'intégration de Storm à Hadoop et l'amélioration de son adaptation aux entreprises.