Les travaux de recherche de Fast Forward Labs désormais disponibles sans abonnement
À l'avenir, tous les nouveaux rapports seront accessibles au public et téléchargeables gratuitement. Nous donnerons également accès à des versions révisées de nos anciens rapports au fil du temps, alors revenez régulièrement consulter les études gratuites disponibles.
Rapports de recherche gratuits
Découvrez nos derniers rapports de recherche et prototypes, en libre accès pour tous.
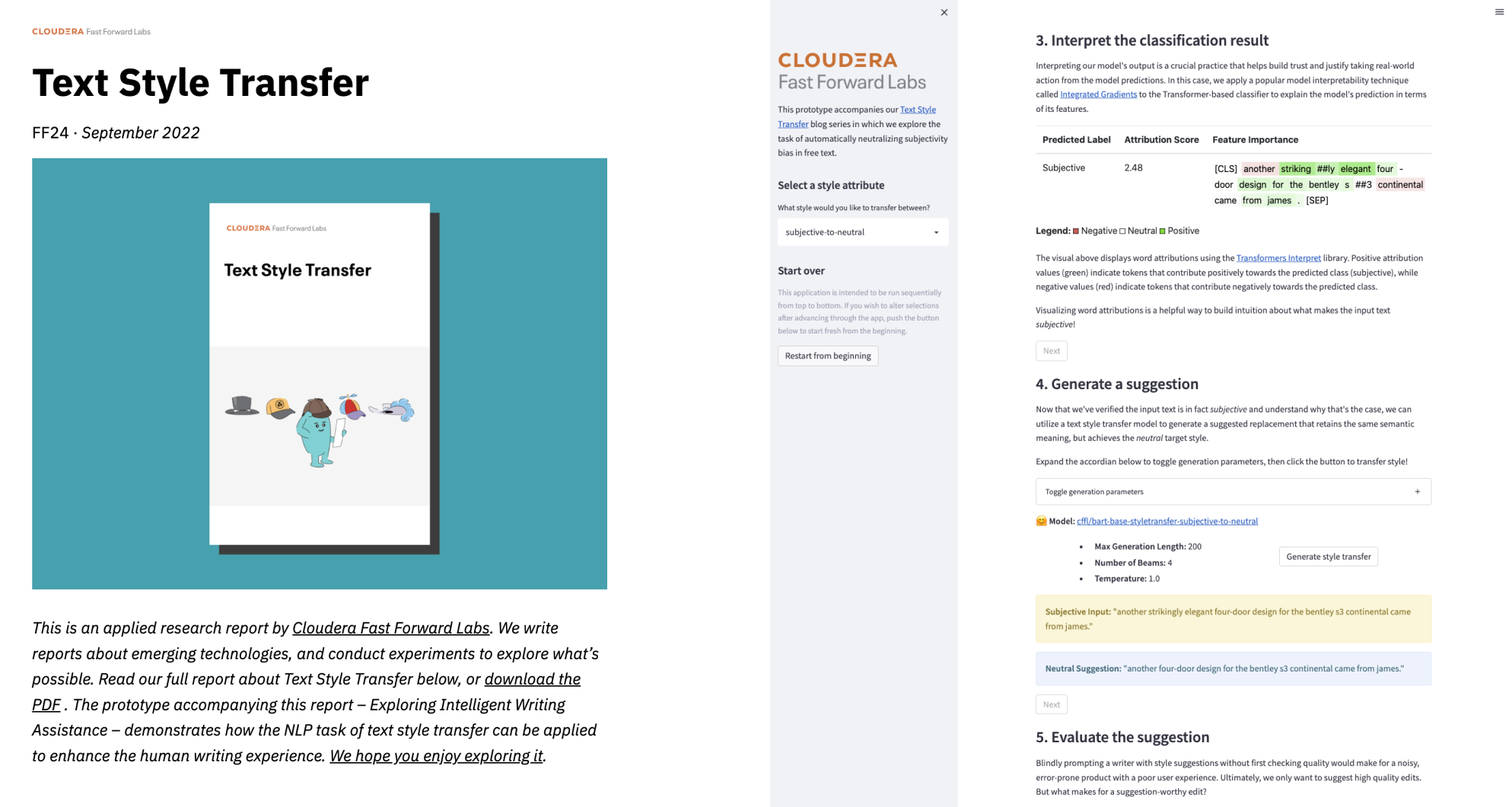
Transfert de style de texte
La tâche de transfert de style de texte du TALN vise à contrôler automatiquement les attributs de style d'un texte tout en préservant le contenu, indispensable pour centrer davantage le TALN sur les utilisateurs. Dans ce rapport, nous explorons le transfert de style de texte par le biais d'un cas d'utilisation appliqué, en neutralisant le biais de subjectivité dans le texte libre. En cours de route, nous décrivons notre approche de modélisation séquence-séquence utilisant HuggingFace Transformers et présentons un ensemble de mesures d'évaluation personnalisées et sans référence pour quantifier les performances du modèle. Enfin, nous concluons avec une discussion sur l'éthique centrée sur notre prototype : explorer l'aide à la rédaction intelligente.
Déduire la dérive conceptuelle sans données étiquetées
La dérive conceptuelle se produit lorsque les propriétés statistiques d'un domaine cible évoluent au cours du temps et dégradent les performances du modèle. Elle se détecte généralement en surveillant un indicateur de performance d'intérêt et en déclenchant un pipeline de recyclage lorsque celui-ci descend en dessous d'un seuil déterminé. Cependant, cette approche suppose que vous disposiez de nombreuses données étiquetées au moment de la prédiction, ce qui constitue une contrainte irréaliste pour de nombreux systèmes de production. Dans ce rapport, nous analysons plusieurs approches permettant de traiter la dérive conceptuelle quand vous n'avez pas de données étiquetées à disposition.

À la découverte de l'optimisation multi-objectif des hyperparamètres
Nous développons des modèles de machine learning en fonction des indicateurs « habituels » tels que l'exactitude prédictive, le rappel et la précision. Cependant, ces indicateurs sont rarement la seule chose qui nous intéresse. Les modèles de production doivent également répondre à des exigences physiques telles que le temps de latence ou l'empreinte mémoire, ou à des contraintes d'équité. L'optimisation des hyperparamètres se corse davantage en présence de plusieurs indicateurs à optimiser. Lors de nos dernières recherches, nous nous sommes penchés en détail sur ce scénario d'optimisation multi-objectif des hyperparamètres.

Le deep learning au service de la vérification automatique des signatures hors ligne
La vérification de signatures manuscrites vise à distinguer automatiquement les signatures authentiques des fausses. Il s'agit d'un enjeu particulièrement important en raison de l'omniprésence des signatures manuscrites comme forme d'identification dans les domaines juridique, financier et administratif. Ce programme de recherche s'est penché sur l'utilisation d'approches de deep learning métrique, en particulier les réseaux siamois, combinées à de nouvelles méthodes d'extraction de caractéristiques visant à améliorer les techniques traditionnelles.

Systèmes de recommandation orientés session
Les systèmes de recommandation sont devenus incontournables dans la vie moderne, que ce soit dans le commerce en ligne, le streaming audio et vidéo, et même l'édition de contenu. Ces systèmes nous aident à nous frayer un chemin parmi la multitude de contenus disponibles sur Internet en nous faisant découvrir ceux susceptibles de nous intéresser. L'une des principales tendances de ces dernières années est celle des algorithmes de recommandation orientés session, qui fournissent des recommandations uniquement sur la base des interactions d'un utilisateur lors de la session en cours, et qui ne nécessitent donc pas de profils utilisateur ni d'un historique complet de ses préférences.

Classification de texte avec peu de données
La classification de texte intervient dans l'analyse des sentiments, l'attribution de thèmes, l'identification de documents, la suggestion d'articles et bien plus encore. Si des dizaines de techniques existent aujourd'hui pour cette tâche qui se veut élémentaire, toutes nécessitent des quantités colossales de données étiquetées pour être utiles. Recueillir des annotations pour votre cas d'utilisation est par définition l'une des facettes les plus coûteuses de toute application du machine learning. Dans ce rapport, nous nous intéressons à la façon dont exploiter des intégrations de texte latentes avec peu ou aucun modèle et mettre en œuvre cette méthode de la meilleure manière possible.

Séries chronologiques structurelles
Les données de séries chronologiques sont partout. Ce rapport est consacré aux modèles additifs généralisés, qui permettent de modéliser les séries temporelles de manière simple, flexible et interprétable en les décomposant en éléments structurels. Nous étudions les avantages et les inconvénients que présente l'ajustement de courbe dans le domaine des séries chronologiques, et donnons un exemple d'utilisation via la bibliothèque Prophet de Facebook sur un problème de prévision de la demande.
Méta-apprentissage
Contrairement aux humains, les algorithmes de deep learning nécessitent de grandes quantités de données et de calculs et peuvent néanmoins éprouver des difficultés à établir des généralités. Lorsqu'ils sont confrontés à de nouveaux problèmes, les humains s'adaptent rapidement en tirant parti des connaissances qu'ils ont acquises lors d'expériences précédentes. Dans ce rapport, nous expliquons comment le méta-apprentissage permet d'exploiter les connaissances acquises antérieurement à partir de données en vue de réaliser de nouvelles tâches rapidement et plus efficacement pendant la période de test.
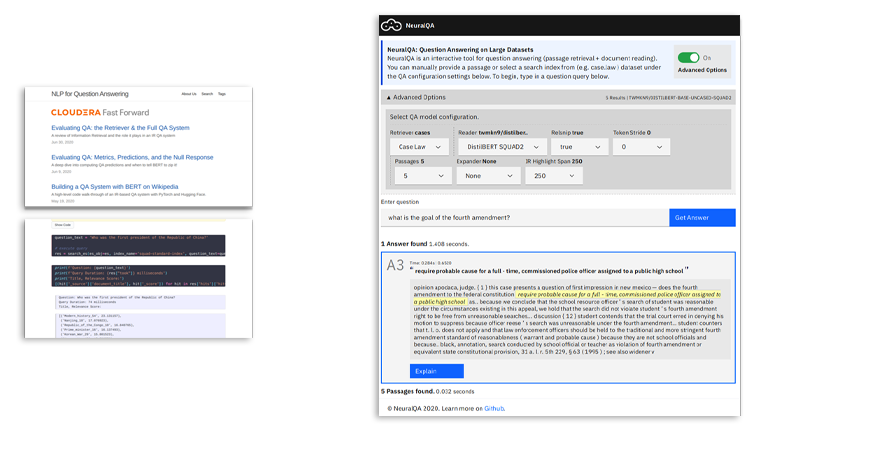
Réponse automatique aux questions
La réponse automatique aux questions consiste à extraire des informations à partir des données de manière conviviale au moyen du traitement automatique du langage naturel. Grâce aux récents progrès en la matière, les capacités de réponse basées sur des données textuelles non structurées se sont rapidement développées. Cette série de blogs étudie en détail les aspects techniques et pratiques liés à l'élaboration complète d'un système de réponse aux questions.
Causalité du machine learning
Domaine de recherche en plein essor, la rencontre entre l'inférence causale et le machine learning permet déjà de concevoir des systèmes de machine learning plus robustes, plus fiables et plus équitables. Ce rapport présente le concept de raisonnement causal à l'aide de graphiques de causalité et de prévisions invariables, et explique comment associer les outils d'inférence causale aux techniques classiques de machine learning dans le cadre de divers scénarios.

Interprétabilité : édition 2020
L'interprétabilité, ou la capacité d'expliquer pourquoi et comment un système prend une décision, nous permet d'améliorer les modèles, de satisfaire aux réglementations et de concevoir de meilleurs produits. Les techniques de type « boîte noire » telles que le deep learning ont permis de réaliser d'immenses progrès au détriment de l'interprétabilité. Dans ce rapport, récemment mis à jour pour inclure des techniques telles que SHAP, nous montrons comment rendre les modèles interprétables sans sacrifier leurs capacités ni leur précision.
Le deep learning au service de la détection des anomalies
De la détection des fraudes au signalement des anomalies dans les données d'imagerie, il existe un nombre incalculable d'applications permettant de repérer automatiquement les données anormales. Or, ce processus peut s'avérer délicat, surtout lorsque l'on travaille avec des données volumineuses et complexes. Ce rapport vous présente les approches de deep learning en matière de détection des anomalies (modèles de séquence, VAE, GAN), leur mise en pratique, des tests de performance ainsi que les produits disponibles.
Le transfer learning pour le traitement automatique du langage naturel
Grâce au deep learning, les technologies de traitement automatique du langage naturel (TALN) sont capables de traduire des langues, de répondre à des questions et de générer des textes réalistes. Cependant, ces techniques de deep learning nécessitent une infrastructure, une expertise ainsi que des ensembles de données coûteux, en grand volume. Le transfer learning fait face à ces contraintes en réutilisant et en adaptant la compréhension du langage d'un modèle. En somme, il s'agit d'une technique parfaitement adaptée aux diverses applications du TALN. Dans ce rapport, vous pourrez découvrir comment vous appuyer sur le transfer learning pour concevoir des systèmes de TALN hautement performants avec un minimum de ressources.

L'apprentissage à partir de données étiquetées limitées
En étant en mesure d'apprendre avec un nombre limité de données étiquetées, l'exigence contraignante de disposer de telles données pour le machine learning supervisé est assouplie. Ce rapport se concentre sur l'active learning, une technique qui repose sur la collaboration entre les machines et les humains pour étiqueter intelligemment les données. L'active learning limite le nombre d'exemples étiquetés requis pour entraîner un modèle, afin de gagner du temps et de l'argent tout en obtenant des performances comparables aux modèles entraînés avec beaucoup plus de données. Grâce à l'active learning, les entreprises peuvent exploiter leur base de données non étiquetées volumineuse afin d'innover en matière de développement de produits.
Federated learning
L'apprentissage fédéré permet de concevoir des systèmes de machine learning sans accès direct aux données d'entraînement, qui restent dans leur emplacement d'origine. Cela renforce la confidentialité et réduit les coûts de communication. Outre aux applications industrielles telles que la maintenance prédictive, l'apprentissage fédéré convient parfaitement aux smartphones et aux équipements edge, au secteur de la santé ainsi qu'aux autres domaines où la confidentialité des données est essentielle.
Recommandations sémantiques
Internet nous a offert une pléthore d'options de lecture, de visionnage et d'achat. Ainsi, les algorithmes de recommandation, capables de trouver des éléments susceptibles d'intéresser une personne en particulier, sont plus importants que jamais. Dans ce rapport, nous nous intéresserons aux systèmes de recommandation qui utilisent le contenu sémantique des éléments et des utilisateurs pour fournir des recommandations enrichies dans plusieurs secteurs.

Synthèse
Ce rapport présente des méthodes de résumé extractif, une compétence qui permet de résumer automatiquement des documents. Cette technique peut être utilisée de bien des façons, comme par exemple pour distiller des milliers d'avis sur des produits, extraire le contenu le plus important de longs articles ou créer automatiquement des profils clients à partir de leurs personas.
Le deep learning pour l'analyse d'images – Édition 2019
Les réseaux neuronaux convolutifs (CNN ou ConvNets) excellent dans la reconnaissance d'images, via des représentations concrètes de leurs caractéristiques et concepts. Ils sont ainsi utilisés pour résoudre divers problèmes dans de nombreux domaines, de l'imagerie médicale au secteur industriel. Dans ce rapport, nous vous montrons quels sont les modèles de deep learning les plus adaptés aux tâches d'analyse d'images, et vous présentons les techniques de débogage de ces modèles.
Deep learning : analyse d'images
Ce rapport retrace l'histoire du deep learning, présente la situation actuelle, explique comment l'appliquer et prévoit ses développements à venir.

Méthodes probabilistes pour flux en temps réel
Depuis l'époque des ordinateurs analogiques construits à l'aide de cames et d'engrenages, nous avons conçu des systèmes axés sur les flux de données et calculs critiques que nous devons exécuter. Si la philosophie de nos conceptions est restée constante, nos contraintes techniques, elles, n'ont de cesse d'évoluer. Ces cinq dernières années, nous avons assisté à l'émergence du « big data », la possibilité d'utiliser une infrastructure de base pour analyser de très grands ensembles de données dans un lot. Nous nous trouvons actuellement à une étape importante en matière d'outils, de méthodes et de technologies disponibles permettant de travailler avec des flux de données en temps réel.

Rapports sur abonnement uniquement
Les versions actualisées des anciens rapports seront disponibles gratuitement à l'avenir, alors revenez de temps en temps.

Apprentissage multitâche
Ce rapport porte sur l'apprentissage multitâche, nouvelle approche du machine learning qui permet aux algorithmes de maîtriser plusieurs tâches en parallèle.
{kind=link}

Programmation probabiliste
Nous expliquons ici comment utiliser la programmation probabiliste et l'inférence bayésienne pour construire facilement des outils qui réalisent de meilleurs prévisions et améliorent la prise de décisions.
{kind=link}

Génération de langage naturel
Ce rapport explique comment les machines peuvent transformer des données hautement structurées en récit rédigé en langue humaine.
Lire le blog Fast Forward Labs
Ne vous laissez pas distancer par demain
Inscrivez-vous à notre newsletter mensuelle et découvrez les dernières avancées de l'intelligence artificielle appliquée, ainsi que l'actualité de l'entreprise et ses événements.